-
Notifications
You must be signed in to change notification settings - Fork 1
/
Copy pathindex.qmd
927 lines (643 loc) · 22.4 KB
/
index.qmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
---
title: "Optimización del Rendimiento en Shiny"
subtitle: "Técnicas y Mejores Prácticas"
author: "Samuel Calderon"
format:
revealjs:
theme: default
transition: slide
slide-number: true
logo: img/Appsilon_logo.svg
footer: "LatinR: 2024-11-18"
mermaid:
theme: default
execute:
eval: false
echo: true
---
## Material
<https://github.com/Appsilon/latin-r-2024>
## Estructura del Taller (3 horas)
- Introducción
- Ciclo de optimización: Ejercicio 1 - Benchmarking
- Profiling: Ejercicio 2
- Optimización - Data: Ejercicio 3
- Optimización - Shiny: Ejercicio 4
- Optimización - Async: Ejercicio 5
- Temas avanzados
- Preguntas
# Introducción
## Appsilon

<https://www.appsilon.com/>
## We are hiring!
- [R shiny developer](https://jobs.lever.co/appsilon/6e6cea0f-4ec3-439a-8456-d5e31e51c05b?lever-origin=ap%5B%E2%80%A6%5Dloper)
- [R developer with life science](https://jobs.lever.co/appsilon/d5c698a5-9f93-4fb4-a22b-b4abaf77de5d?lever-origin=applied&lever-source%5B%5D=CAREERS)
- [Project Manager (US time zone)](https://jobs.lever.co/appsilon/e8594bfe-2c9a-4504-b978-ff3242bc9c73?lever-origin=applied&lever-source%5B%5D=careers%20page?utm_medium%3Djob-boards)
Para ver más posiciones: <https://www.appsilon.com/careers>
## Quién soy
- Politólogo y ahora R shiny developer
- De Lima, Perú
- Contacto:
- Web: <https://www.samuelenrique.com>
- Github: <https://github.com/calderonsamuel>
- Linkedin: <https://www.linkedin.com/in/samuelcalderon/>
## ¿Quiénes son ustedes?
- Compartir en el chat:
- Nombre
- De dónde son y qué hora es en su ciudad
- Background profesional (brevísimo)
- 3 paquetes de R favoritos (si son de nicho, mejor)
# Ciclo de Optimización
## Primero lo primero
¿Qué es una computadora? La interacción de 3 componentes principales

## ¿Qué es optimizar?

¡Depende de la necesidad!
En general, pensemos en tiempo (CPU) o espacio (memory/storage). El dinero es un eje secreto.
## El ciclo graficado

<https://www.appsilon.com/post/optimize-shiny-app-performance>
## A saber en cada etapa
- Benchmarking: ¿Performa como esperamos?
- Profilling: ¿Dónde están los cuellos de botella?
- Estimación/Recomendación: ¿Qué puedo hacer?
- Optimización: Tomar decisión e implementar
## Tipos de benchmarking
- Manual
- Avanzado ([shinyloadtest](https://rstudio.github.io/shinyloadtest/index.html)):
## Ejercicio 1 - Benchmarking

---
- Prueba la app y anota cuánto tiempo te toma ver la información para:
- 3 ciudades diferentes
- 3 edades máximas diferentes
Enlace: <https://01933b4a-2e76-51f9-79f4-629808c48a59.share.connect.posit.cloud/>
# Profiling
## Profiling - Herramientas en R
El profiling es una técnica utilizada para identificar cuellos de botella en el rendimiento de tu código:
## `{profvis}`
Es una herramienta interactiva que proporciona una visualización detallada del tiempo de ejecución de tu código.
- Instalación:
```{r}
install.packages("profvis")
```
- Uso básico:
```{r}
library(profvis)
profvis({
# Código a perfilar
})
```
## shiny.tictoc
Una herramienta que usa Javascript para calcular el tiempo que toman las acciones en la app, desde el punto de vista del navegador.
Es super fácil de añadir a una app.
```{r}
tags$script(
src = "https://cdn.jsdelivr.net/gh/Appsilon/shiny.tictoc@v0.2.0/shiny-tic-toc.min.js"
)
```
- Si no saben añadir JS: [Packaging Javscript code for Shiny](https://shiny.posit.co/r/articles/build/packaging-javascript/)
---
Ejecutar cualquiera de estas operaciones en la consola de Javascript.
```js
// Print out all measurements
showAllMeasurements()
// To download all measurements as a CSV file
exportMeasurements()
// To print out summarised measurements (slowest rendering output, slowest server computation)
showSummarisedMeasurements()
// To export an html file that visualizes measurements on a timeline
await exportHtmlReport()
```
Muchos navegadores cuentan con herramientas de desarrollador donde puedes encontrar una mientras tu app está corriendo.
## Usando profvis
Ubicar la herramienta en Rstudio

---
La consola de R mostrará el botón "Stop profiling". Esto significa que el profiler está activado.

Corre tu shiny app e interactúa con ella. Luego, puedes detener la app y el profiler.
---
El panel de edición de Rstudio te mostrará una nueva vista.

La parte superior hace profiling de cada línea de código, la parte inferior muestra un *FlameGraph*, que indica el tiempo requerido por cada operación.
---
También puede accederse a la pestaña "Data".

Esta indica cuánto tiempo y memoria se ha requerido por cada operación. Nos da un resumen de la medición.
---
Para una revisión más exhaustiva del uso de `{profvis}`, puedes consultar la documentación oficial:
- Ejemplos: <https://profvis.r-lib.org/articles/rstudio.html>
- Integración con RStudio: <https://profvis.r-lib.org/articles/rstudio.html>
## Ejercicio 2 - Profiling
Realiza el profiling del archivo "app.R".
- Interpreta los resultados
- ¿Cuáles son los puntos más críticos?
Toma en cuenta que estás probando esto para un solo usuario.
## Optimización - Data
1. Usar opciones más rápidas para cargar datos
2. Usar formatos de archivo más eficientes
3. Pre-procesar los cálculos
4. Usar bases de datos. Puede requerir aprender SQL.
¡Puedes combinar todo!
## Cargar datos más rápido
- data.table::fread()
- vroom::vroom()
- readr::read_csv()
## Ejemplo
NO ejecutar durante el workshop porque toma tiempo en correr
```r
suppressMessages(
microbenchmark::microbenchmark(
read.csv = read.csv("data/personal.csv"),
read_csv = readr::read_csv("data/personal.csv"),
vroom = vroom::vroom("data/personal.csv"),
fread = data.table::fread("data/personal.csv")
)
)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> read.csv 1891.3824 2007.2517 2113.5217 2082.6016 2232.7825 2442.6901 100
#> read_csv 721.9287 820.4181 873.4603 866.7321 897.3488 1165.5929 100
#> vroom 176.7522 189.8111 205.2099 197.9027 206.2619 495.2784 100
#> fread 291.9581 370.8261 410.3995 398.9489 439.7827 638.0363 100
```
## Formatos de datos eficientes:
- Parquet (via {arrow})
- Feather (compatibilidad con Python)
- fst
- RDS (nativo de R)
## Ejemplo
NO ejecutar durante el workshop porque toma tiempo en correr
```r
suppressMessages(
microbenchmark::microbenchmark(
read.csv = read.csv("data/personal.csv"),
fst = fst::read_fst("data/personal.fst"),
parquet = arrow::read_parquet("data/personal.parquet"),
rds = readRDS("data/personal.rds")
)
)
#> Unit: milliseconds
#> expr min lq mean median uq max neval
#> read.csv 1911.2919 2075.26525 2514.29114 2308.57325 2658.03690 4130.748 100
#> fst 201.1500 267.85160 339.73881 308.24680 357.19565 834.646 100
#> parquet 64.5013 67.29655 84.48485 70.70505 87.81995 405.147 100
#> rds 558.5518 644.32460 782.37898 695.07300 860.85075 1379.519 100
```
## Pre-procesar cálculos
- Filtrado previo: Menos tamaño
- Transformación o agregación previa: Menos tiempo
- Uso de índices: Búsqueda rápida
Es, en esencia, *caching*. Personalmente, mi estrategia favorita.
Difícil de usar si se requiere calcular en vivo, real-time (stock exchange, streaming data), o la data no puede ser guardada en cualquier lugar (seguridad, privacidad).
## Sin pre-procesamiento
```{r}
# app.R
survey <- read.csv("data/survey.csv")
server <- function(input, output) {
output$table <- renderTable({
survey |>
filter(region == input$region) |>
summarise(avg_time = mean(temps_trajet_en_heures))
})
}
```
## Con pre-procesamiento
```{r}
# script.R
survey <- read.csv("data/survey.csv")
regions <- unique(survey$region)
values <- regions |>
lapply(function(x) {
survey |>
dplyr::filter(region == x) |>
dplyr::summarise(avg_time = mean(temps_trajet_en_heures))
}) |>
setNames(regions)
saveRDS(values, "data/values.rds")
```
```{r}
# app.R
values <- readRDS("data/values.rds")
server <- function(input, output) {
output$table <- renderTable(values[[input$region]])
}
```
## Bases de Datos relacionales
- **Escalabilidad**: Las bases de datos pueden manejar grandes volúmenes de datos de manera eficiente.
- **Consultas Rápidas**: Permiten realizar consultas complejas de manera rápida.
- **Persistencia**: Los datos se almacenan de manera persistente, lo que permite su recuperación en cualquier momento.
---
Algunos ejemplos notables son SQLite, MySQL, PostgreSQL, DuckDB.
[freeCodeCamp](https://www.freecodecamp.org/learn/relational-database/) tiene un buen curso para principiantes.
## Ejercicio 3 - Data
Implementa una estrategia de optimización
# Optimización - Shiny
## Cuando una app arranca

---
Del lado de shiny, optimizar consiste básicamente en hacer que la app (en realidad, el procesador) haga el menor trabajo posible.
## Reducir reactividad
```{r}
#| code-line-numbers: "|3,4,5,9,10,11"
server <- function(input, output, session) {
output$table <- renderTable({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
})
output$histogram <- renderPlot({
survey |>
filter(region == input$region) |>
filter(age <= input$age) |>
ggplot(aes(temps_trajet_en_heures)) +
geom_histogram(bins = 20) +
theme_light()
})
}
```
---
`reactive()` al rescate
```{r}
#| code-line-numbers: "|2-6|9,13"
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
})
output$table <- renderTable({
filtered()
})
output$histogram <- renderPlot({
filtered() |>
ggplot(aes(temps_trajet_en_heures)) +
geom_histogram(bins = 20) +
theme_light()
})
}
```
::: aside
Usamos más de espacio (memoria) para reducir tiempo (CPU)
:::
## Controlar reactividad
Puedes encadenar `bindEvent()` a un `reactive()` u `observe()`.
```{r}
my_reactive <- reactive({
# slow reactive computation
}) |>
bindEvent(input$trigger)
observe({
# slow reactive side effect
}) |>
bindEvent(input$trigger)
```
::: aside
En versiones pasadas, esto se hacía con `observeEvent()` o `eventReactive()`.
:::
---
```{r}
#| code-line-numbers: "|5|16"
ui <- page_sidebar(
sidebar = sidebar(
selectInput(inputId = "region", ...),
sliderInput(inputId = "age", ...),
actionButton(inputId = "compute", label = "Calcular")
),
...
)
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
}) |>
bindEvent(input$compute, ignoreNULL = FALSE)
}
```
Ahora `filtered()` solo se actualizará cuando haya interacción con `input$compute`.
::: aside
`ignoreNULL = FALSE` permite ejecutar el `reactive()` al iniciar la app.
:::
## Estrategias de Caché
`bindCache()` nos permite guardar cómputos al vuelo en base a ciertas *keys*.
```{r}
#| code-line-numbers: "|7"
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
}) |>
bindCache(input$region, input$age) |>
bindEvent(input$compute, ignoreNULL = FALSE)
}
```
Cuando una combinación vuelva a aparecer, se leerá el valor en lugar de recalcularlo.
::: aside
`bindEvent()` no es obligatorio para usar `bindCache()`.
:::
---
2. Niveles de caché:
- Nivel aplicación: `cache = "app"` (default)
- Nivel sesión: `cache = "session"`
- Personalizado: `cache object + opciones`
```{r}
bindCache(..., cache = "app")
```
Por defecto, se usará un máximo de 200 Mb de caché.
::: aside
Potencialmente mucho uso de memoria/storage, para reducir tiempo de procesamiento.
:::
## Comunicación servidor - navegador
- Enviar datos desde el servidor hacia el navegador toma tiempo.
- Datos grandes -> mayor tiempo de envío.
- Conexión lenta -> mayor tiempo de envío
- Igualmente, si los datos son grandes, al navegador le cuesta más leerlos y mostrarlos al usuario.
Puede que la PC del usuario sea una tostadora!
---
- ¿Qué hacer?
- Reducir frecuencia de envíos (`bindEvent()`)
- Reducir tamaño de envíos
- Mandar lo mismo pero en partes más pequeñas (server-side processing o streaming)
## Reducir tamaño de envíos
Es posible delegar ciertos cálculos al navegador. Por ejemplo, renderizar un gráfico con [`{plotly}`](https://plotly.com/ggplot2/) en lugar de `{ggplot2}`.
```{r}
plotly::plotlyOutput() # en lugar de plotOutput
plotly::renderPlotly() # en lugar de renderPlot
```
Con ello, se manda la "receta" del gráfico en lugar del gráfico mismo. Al recibir la receta, el navegador se encarga de renderizarla.
---
Estas funciones traducen sintaxis de `ggplot2` a sintaxis de `plotly.js` de manera bastante eficiente. Tiene soporte para muchos tipos de gráficos.

Pero no te confíes, en muchos casos, el código va a necesitar retoques. Especialmente al usar extensiones de `ggplot2`.
---
Otros paquetes similares:
- [ggiraph](https://davidgohel.github.io/ggiraph/)
- [echarts4r](https://echarts4r.john-coene.com/)
- [highcharter](https://jkunst.com/highcharter/)
- [r2d3](https://rstudio.github.io/r2d3/)
- [shiny.gosling](https://appsilon.github.io/shiny.gosling/index.html) (genomics, by Appsilon)
## Server-side processing
En el caso de las tablas, el server-side processing permite paginar el resultado y enviar al navegador solo la página que está siendo mostrada en el momento.
El paquete `{DT}` es una opción solida.
```{r}
DT::DTOutput() # en lugar de tableOutput()
DT::renderDT() # en lugar de renderTable()
```
::: aside
Si ya usabas `{DT}`, ¿sabías que hacía esto por defecto?
:::
---
Otra opcion:
- `{reactable}` en conjunto con `{reactable.extras}` (by Appsilon).
## Ejercicio 4 - Shiny
Implementa alguna de las optimizaciones mencionadas.
# Optimización - Async
## Programación síncrona
::: {.columns}
::: {.column}
- Las tareas se ejecutan secuencialmente
- Es fácil de entender e implementa
:::
::: {.column}

:::
:::
Ejemplo: Una cocina con una hornilla. Si empecé a freir pollo, no puedo freir nada hasta terminar de freir el pollo.
## Proramación asíncrona
::: {.columns}
::: {.column}
- Las tareas pueden iniciar y ejecutarse independientemente
- Mientras se procesa una tarea, otras pueden ser iniciadas o completadas.
:::
::: {.column}

:::
:::
Ejemplo: Una cocina con múltiples hornillas. Si empecé a freir pollo en una hornilla, puedo freir otra cosa en una hornilla diferente.
---
Hornilla == Proceso en la PC
::: {.callout-warning title="Cuidado"}
A más hornillas, también es más fácil quemar la comida!
:::
## Posibles complicaciones
- El código se hace más dificil de entender
- Sin adecuado control, pueden sobreescribir sus resultados
- Lógica circular. Proceso A espera a Proceso B, quien espera a Proceso A
- Incrementa la dificultad para hacer debugging porque los errores ocurren en otro lado
- Mayor consumo de energía
## Beneficios
- Operaciones largas no bloquean a otras operaciones
- Flexibilidad: mi sistema se adapta a retrasos inesperados
- La aplicación se mantiene responsiva, no se "cuelga"
- Uso eficiente de recursos. "Pagué por 8 procesadores y voy a usar 8 procesadores".
- Escalabilidad a otro nivel
## Casos de uso
- Operaciones I/O:
- Query a bases de datos
- Solicitudes a APIs
- Cálculos intensivos
## ¿Qué necesito?
- CPU con varios núcleos/hilos.
- Paquetes:
- {promises}
- {future}
- ExtendedTask (Shiny 1.8.1+)
::: {.callout-note title="Nota"}
ExtendedTask es un recurso bastante nuevo. También es posible usar solo `future()` o `future_promise()` dentro de un reactive para lograr un efecto similar, aunque con menos ventajas.
:::
## Setup inicial
```{r}
#| code-line-numbers: "|4-7"
library(shiny)
library(bslib)
library(tidyverse)
library(future)
library(promises)
plan(multisession)
survey <- arrow::read_parquet("data/survey.parquet")
```
Esto le dice al proceso que corre la app que los *futures* creados se resuelvan en sesiones paralelas.
## Procedimiento
1. Crear un objeto `ExtendedTask`.
2. Hacer bind a un task button
3. Invocar la tarea
4. Recuperar los resultados
<https://shiny.posit.co/r/articles/improve/nonblocking/>
## Punto de partida - UI
```{r}
#| code-line-numbers: "|5"
ui <- page_sidebar(
sidebar = sidebar(
selectInput(inputId = "region", ...),
sliderInput(inputId = "age", ...),
actionButton(inputId = "compute", label = "Calcular")
),
...
)
```
## Modificaciones - UI
```{r}
#| code-line-numbers: "5"
ui <- page_sidebar(
sidebar = sidebar(
selectInput(inputId = "region", ...),
sliderInput(inputId = "age", ...),
input_task_button(id = "compute", label = "Calcular")
),
...
)
```
Cambiamos el `actionButton()` por `bslib::input_task_button()`. Este botón tendrá un comportamiento especial.
## Punto de partida - Server
```{r}
#| code-line-numbers: "|3-5|8|7"
server <- function(input, output, session) {
filtered <- reactive({
survey |>
filter(region == input$region) |>
filter(age <= input$age)
}) |>
bindCache(input$region, input$age) |>
bindEvent(input$compute, ignoreNULL = FALSE)
output$table <- DT::renderDT(filtered())
...
}
```
## Modificaciones - Server
```{r}
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
future_promise({
p_survey |>
dplyr::filter(region == p_region) |>
dplyr::filter(age <= p_age)
})
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}
```
## Modificaciones - Server
Paso 1: Se creó un `ExtendedTask` que envuelve a una función.
```{r}
#| code-line-numbers: "|2|4-6|3,7"
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
future_promise({
p_survey |>
dplyr::filter(region == p_region) |>
dplyr::filter(age <= p_age)
})
}) |>
bind_task_button("compute")
...
}
```
Dentro de la función, tenemos la lógica de nuestro cálculo envuelta en un `future_promise()`. La función asume una sesión en blanco.
## Modificaciones - Server
Paso 2: Se hizo bind a un task button
```{r}
#| code-line-numbers: "|5,8"
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(...) {
...
}) |>
bind_task_button("compute")
observe(...) |>
bindEvent(input$compute, ignoreNULL = FALSE)
...
}
```
::: {.callout-note title="Nota"}
`bind_task_button()` requiere el mismo id que `input_task_button()`. `bindEvent()` acepta cualquier reactive.
:::
## Modificaciones - Server
Paso 3: Invocar la tarea con `ExtendedTask$invoke()`.
```{r}
#| code-line-numbers: "|2,7"
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
...
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}
```
Se le provee la data necesaria para trabajar. Tomar en cuenta que `invoke()` no tiene valor de retorno (es un side-effect).
## Modificaciones - Server
Paso 4: Recuperar los resultados con `ExtendedTask$result()`.
```{r}
#| code-line-numbers: "|10|12"
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(...) {
...
}) |>
bind_task_button("compute")
observe(filter_task$invoke(...)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}
```
`result()` se comporta como cualquier reactive.
## Modificaciones - Server
```{r}
server <- function(input, output, session) {
filter_task <- ExtendedTask$new(function(p_survey, p_region, p_age) {
future_promise({
p_survey |>
dplyr::filter(region == p_region) |>
dplyr::filter(age <= p_age)
})
}) |>
bind_task_button("compute")
observe(filter_task$invoke(survey, input$region, input$age)) |>
bindEvent(input$compute, ignoreNULL = FALSE)
filtered <- reactive(filter_task$result())
output$table <- DT::renderDT(filtered())
...
}
```
¡Perdimos el cache! `ExtendedTask()` no es 100% compatible con las estrategias de caching vistas.
## Ejercicio 5 - Async
- Implementa async para uno de los gráficos
- Discusión: ¿vale la pena?
## Todo junto
Acá se desplegó la app con todas las mejoras vistas en los ejercicios. Además, `survey` utiliza la data completa, en lugar de una muestra por región.
Enlace: <https://01933e23-3162-29f7-ec09-ce351b4b4615.share.connect.posit.cloud/->
::: aside
La plataforma permitió 8 GB de RAM y 2 núcleos de CPU.
:::
# Temas avanzados
## Representando la complejidad
[Big O notation](https://www.freecodecamp.org/news/big-o-notation-why-it-matters-and-why-it-doesnt-1674cfa8a23c/)
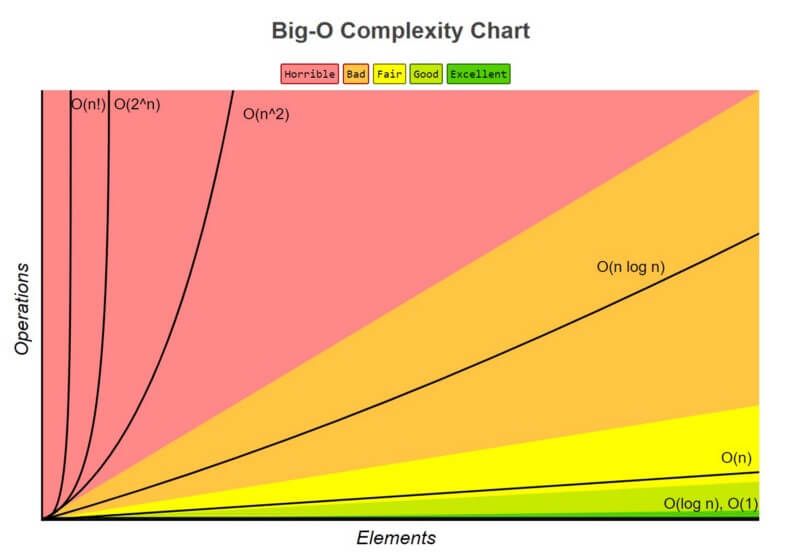
## Entendiendo la complejidad
[Algoritmos y estructuras de datos](https://blog.algomaster.io/p/how-i-mastered-data-structures-and-algorithms)
## Enfrentando la complejidad
- Modularización
- [shiny](https://mastering-shiny.org/scaling-modules.html)
- [box](https://github.com/klmr/box)
- [Testing](https://mastering-shiny.org/scaling-testing.html)
- File structure
¡[`{rhino}`](https://appsilon.github.io/rhino/) tiene todo esto!
# Preguntas
# ¡Gracias!
- Web: <https://www.samuelenrique.com>
- Github: <https://github.com/calderonsamuel>
- Linkedin: <https://www.linkedin.com/in/samuelcalderon/>