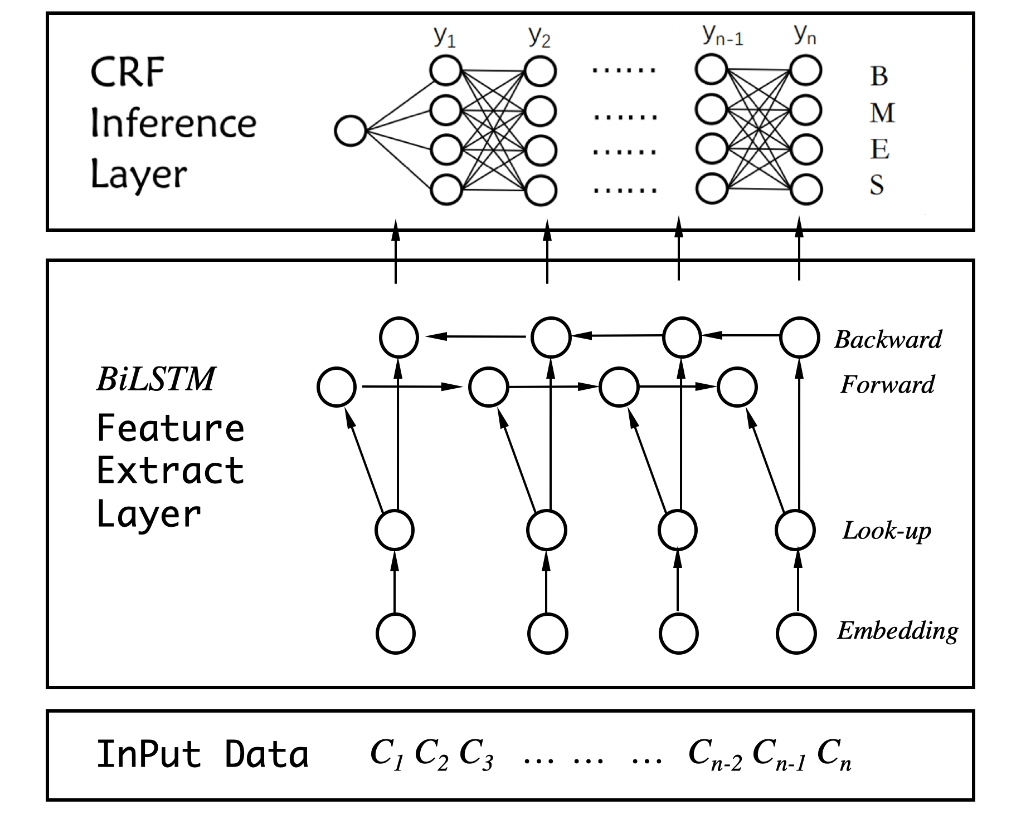
- B: begin of a token
- M: middle of a token
- E: end of a token
- S: single character as a token
- (O: Out of tags)
- Data preprocessing into the classification problem
- Word representation
- One-hot
- TF-IDF
- ...
- Training model for some epochs
- Evaluate in Dev croups
- Predict in best evaluation epochs and generate result


| Model | embed | Train p | Train r | Train f1 | Dev p | Dev r | Dev f1 | Test p | Test n | Test f1 | Best Epoch |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CRF | One-Hot | 98.86 | 99.19 | 99.03 | 76.36 | 75.06 | 75.70 | 78.54 | 75.68 | 77.08 | 130 |
| CRF | Tf_idf | 33.87 | 29.69 | 31.64 | 31.14 | 37.42 | 33.99 | 31.69 | 37.42 | 34.32 | 90 |
| CRF | FastText | 30.24 | 33.21 | 31.65 | 34.59 | 37.29 | 35.89 | 36.13 | 37.99 | 37.03 | 50 |
| BiLSTM-CRF | One-Hot | 94.46 | 95.19 | 94.83 | 90.02 | 91.08 | 90.55 | 91.01 | 91.32 | 91.16 | 8-75 |
There is the significant trouble in our work.
In the design processing, we make the sequence pad to MAX_LEN sequence.
But in the actual, we find that it will be memory error if we pad to max sequence.
There are 513878 char in our Train Set.
But if we pad the seq to the MAX_LEN, it will change to 6106 * 1060 = 6472360.
And if we use one-hot to do the word representation, it will cost 6106 seq * 1060 char * 2849 dim * int16 = 68GB
In fact, the memory will bigger than 120GB.
So the only way is to reshape the sequence.
Initializing tensorflow Variable with an array larger than 2GB
train_x_init = tf.placeholder(tf.float32, shape=np.array(train_x).shape)
train_x_t = tf.Variable(train_x_init)
session.run(tf.global_variables_initializer(), feed_dict={train_x_init: train_x})check the script and find the 391 row in 'pos_evaluation.py' have error in our dataSet.
- crf one-hot -> 120GB+
- BiLSTM-CRF -> 42GB+
NotImplementedError: Failed in object mode pipeline (step: analyzing bytecode) Use of unknown opcode BUILD_MAP_UNPACK at
In numba all thing you can do is to loop.
- icwb2-data - Second International Chinese Word Segmentation Bakeoff 2 Data
- ZHWiki latest pages articles
Pure CRF
- guokr/gkseg - Yet another Chinese word segmentation package based on character-based tagging heuristics and CRF algorithm
Bi-LSTM
Embed in Chinese
- TensorFlow Examples - bidirectional_rnn.py
- RIP Tutorial - Creating a bidirectional LSTM
- tf.nn.bidirectional_dynamic_rnn
- tf.keras.layers.Bidirectional
| id | train | dev |
|---|---|---|
| 0 | 23.40 | 24.62 |
| 10 | 40.06 | 34.21 |
| 20 | 56.65 | 34.55 |
| 30 | 46.59 | 57.50 |
| 40 | 50.16 | 54.88 |
| 50 | 46.53 | 57.44 |
| 60 | 50.47 | 55.57 |
| 70 | 66.09 | 58.75 |
| 80 | 81.50 | 62.65 |
| 90 | 96.89 | 71.10 |
| 100 | 98.54 | 75.22 |
| 110 | 99.03 | 75.70 |
| 120 | 99.40 | 75.56 |
| 130 | 99.69 | 75.53 |
| 140 | 99.87 | 75.61 |
| 150 | 99.94 | 75.65 |
| 160 | 99.98 | 75.56 |
| 170 | 99.99 | 75.59 |
| 180 | 99.99 | 75.59 |
| 190 | 99.99 | 75.55 |
| 200 | 99.99 | 75.56 |
| 210 | 99.99 | 75.57 |
| 220 | 99.99 | 75.57 |
| 230 | 99.99 | 75.57 |
| 240 | 99.99 | 75.53 |
| 250 | 99.99 | 75.49 |
| 260 | 99.99 | 75.53 |
| 270 | 99.99 | 75.50 |
| 280 | 99.99 | 75.48 |
| 290 | 99.99 | 75.49 |
| id | train | dev | test |
|---|---|---|---|
| 0.94 | 82.28 | 80.91 | 82.02 |
| 1.18 | 83.36 | 81.70 | 83.07 |
| 1.37 | 84.60 | 83.08 | 84.53 |
| 1.56 | 85.51 | 83.95 | 85.02 |
| 1.75 | 86.53 | 84.93 | 85.96 |
| 1.94 | 87.08 | 84.82 | |
| 2.18 | 87.41 | 85.69 | 86.49 |
| 2.37 | 88.18 | 86.55 | 87.65 |
| 2.56 | 88.57 | 87.07 | 87.60 |
| 2.75 | 89.15 | 87.16 | 88.12 |
| 2.94 | 89.48 | 87.46 | 88.26 |
| 3.18 | 89.21 | 87.19 | 87.71 |
| 3.37 | 90.01 | 87.91 | 88.71 |
| 3.56 | 90.37 | 88.49 | 88.86 |
| 3.75 | 90.94 | 88.85 | 89.68 |
| 3.94 | 91.10 | 88.70 | |
| 4.18 | 90.94 | 88.33 | 89.11 |
| 4.37 | 91.59 | 88.81 | 89.86 |
| 4.56 | 91.77 | 89.50 | 90.08 |
| 4.75 | 92.01 | 89.47 | |
| 4.94 | 92.16 | 89.36 | |
| 5.18 | 91.79 | 88.90 | 89.49 |
| 5.37 | 92.61 | 89.61 | 90.78 |
| 5.56 | 92.60 | 89.66 | 90.57 |
| 5.75 | 92.97 | 89.94 | 91.01 |
| 5.94 | 93.00 | 89.67 | |
| 6.18 | 92.59 | 89.46 | 90.10 |
| 6.37 | 93.10 | 90.08 | 90.71 |
| 6.56 | 93.17 | 90.06 | |
| 6.75 | 93.57 | 90.02 | |
| 6.94 | 93.62 | 89.78 | |
| 7.18 | 93.16 | 89.32 | 90.02 |
| 7.37 | 93.73 | 90.12 | 90.72 |
| 7.56 | 93.93 | 90.34 | 90.95 |
| 7.75 | 94.26 | 90.31 | |
| 7.94 | 94.40 | 90.23 | |
| 8.18 | 93.90 | 89.45 | 90.36 |
| 8.37 | 94.45 | 90.14 | 90.95 |
| 8.56 | 94.56 | 90.28 | 90.68 |
| 8.75 | 94.83 | 90.55 | 91.16 |
| 8.94 | 94.93 | 90.12 | |
| 9.18 | 94.75 | 89.70 | 90.46 |
| 9.37 | 95.03 | 90.15 | 91.04 |
| 9.56 | 95.11 | 90.44 | 90.77 |
| 9.75 | 95.36 | 90.22 | |
| 9.94 | 95.29 | 89.96 | |
| 10.18 | 95.24 | 89.54 | 90.37 |
| 10.37 | 95.34 | 90.04 | 90.93 |
| 10.56 | 95.68 | 89.99 | |
| 10.75 | 95.72 | 89.77 | |
| 10.94 | 95.45 | 89.60 | |
| 11.18 | 96.03 | 89.90 | 90.83 |
| 11.37 | 95.85 | 90.16 | 91.00 |
| 11.56 | 96.06 | 90.05 | |
| 11.75 | 95.95 | 89.98 | |
| 11.94 | 96.11 | 90.13 | |
| 12.18 | 95.97 | 89.25 | 90.66 |
| 12.37 | 96.45 | 89.61 | 91.15 |
| 12.56 | 96.28 | 89.44 | |
| 12.75 | 96.44 | 89.70 | 90.95 |
| 12.94 | 96.52 | 89.91 | 90.93 |
| 13.18 | 96.13 | 89.28 | 90.41 |
| 13.37 | 96.35 | 89.25 | |
| 13.56 | 96.72 | 89.80 | 90.59 |
| 13.75 | 96.74 | 89.68 | |
| 13.94 | 96.79 | 89.67 | |
| 14.18 | 97.04 | 89.23 | 90.54 |
| 14.37 | 96.66 | 89.28 | 90.61 |
| 14.56 | 96.67 | 89.29 | 90.61 |
| 14.75 | 96.61 | 89.77 | 90.92 |
| 14.94 | 97.10 | 89.36 | |
| 15.18 | 97.42 | 89.09 | 90.36 |
| 15.37 | 97.15 | 89.76 | 90.61 |
| 15.56 | 97.25 | 90.01 | 90.65 |
| 15.75 | 96.94 | 89.74 | |
| 15.94 | 97.28 | 88.88 | |
| 16.18 | 97.36 | 89.06 | 90.23 |
| 16.37 | 97.22 | 89.70 | 90.87 |
| 16.56 | 97.23 | 89.18 | |
| 16.75 | 97.65 | 89.66 | |
| 16.94 | 96.66 | 88.31 | |
| 17.18 | 97.51 | 89.54 | 90.84 |
| 17.37 | 97.67 | 89.77 | 90.96 |
| 17.56 | 97.05 | 88.64 | |
| 17.75 | 97.70 | 89.67 | |
| 17.94 | 96.98 | 88.36 | |
| 18.18 | 97.21 | 89.28 | 91.02 |
| 18.37 | 97.94 | 89.38 | 90.69 |
| 18.56 | 97.97 | 89.58 | 90.55 |
| 18.75 | 97.73 | 89.73 | 91.37 |
| 18.94 | 97.59 | 88.75 | |
| 19.18 | 97.95 | 89.19 | 91.12 |
| 19.37 | 97.41 | 89.14 | |
| 19.56 | 97.87 | 89.47 | 90.55 |
| 19.75 | 97.91 | 89.58 | 90.67 |
| 19.94 | 97.93 | 89.50 | |
| 20.18 | 97.52 | 88.81 | 89.79 |
| 20.37 | 97.22 | 89.37 | 90.84 |
| 20.56 | 97.44 | 89.33 | |
| 20.75 | 97.88 | 90.03 |