




![]()
开发机器学习算法时,我们经常面临一些困扰:
- 配置文件如 YAML / YACS / MMCV 冗长复杂。条目间如果相互依赖,修改时还需格外小心,容易出错。
- 调参时,需要为每组参数重写配置,代码大量重复,且修改部分不易追踪。
- 调参时,需要手动遍历参数空间并汇总结果,耗时且效率低下。
- 调参不充分,埋没了有效的设计。
- 调参不充分,方法虽然有效,但性能不及SOTA,工作说服力不够。
AlchemyCat 是一个专为算法研究设计的配置系统,旨在解决上述困扰。AlchemyCat 通过简化复现、修改配置和调参等重复性工作,帮助研究者迅速穷尽算法的调参潜力。
下表对比了 AlchemyCat 和现有的配置系统(😡不支持,🤔有限支持,🥳支持):
| 功能 | argparse | yaml | YACS | mmcv | AlchemyCat |
|---|---|---|---|---|---|
| 可复现 | 😡 | 🥳 | 🥳 | 🥳 | 🥳 |
| IDE跳转 | 😡 | 😡 | 🥳 | 🥳 | 🥳 |
| 继承 | 😡 | 😡 | 🤔 | 🤔 | 🥳 |
| 组合 | 😡 | 😡 | 🤔 | 🤔 | 🥳 |
| 依赖 | 😡 | 😡 | 😡 | 😡 | 🥳 |
| 自动调参 | 😡 | 😡 | 😡 | 😡 | 🥳 |
可以看到,AlchemyCat 囊括了当前流行的配置系统所提供的所有功能,且充分考虑了各种细节,稳定性有保障。其独到之处还在于:
- 可读:语法简洁、优雅、Pythonic。
- 可复用:支持配置的继承和组合,有效减少冗余,提高配置的复用性。
- 可维护:支持在配置项间建立依赖关系,实现一处更改,全局同步,大大减轻修改配置时的心智负担。
- 支持自动调参并汇总结果,且无需修改原有的标准配置或训练代码。
如果您已经在使用上表中某个配置系统,迁移到 AlchemyCat 是零成本的。花15分钟阅读文档,并将 AlchemyCat 运用到项目中,从此你的GPU将永无空闲!
深度学习依赖于众多经验性的超参数,包括学习率、损失权重、迭代次数、滑动窗口大小、drop path概率、各种阈值,乃至于随机种子。
超参数-性能间的关系难以被理论预测。唯一可以肯定的是,拍脑袋选择的超参数很难达到最优。实践证明,通过网格搜索来遍历超参空间,能够显著提升模型性能,其效果有时甚至超过所谓的『创新点』。能否斩获 SOTA,往往取决于此!
AlchemyCat 提供一台自动调参机,它能够无缝集成现有配置系统,自动探索超参空间并汇总实验结果。使用该工具,用户无需对原始配置或训练代码做任何修改。
以 MMSeg 为例,用户仅需编写一个可调配置,其继承自 MMSeg 提供的基配置,定义了参数的搜索空间:
# -- configs/deeplabv3plus/tune_bs,iter/cfg.py --
from alchemy_cat import Cfg2Tune, Param2Tune
# Inherit from standard mmcv config.
cfg = Cfg2Tune(caps='configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb4-40k_voc12aug-512x512.py')
# Inherit and override
cfg.model.auxiliary_head.loss_decode.loss_weight = 0.2
# Tuning parameters: grid search batch_size and max_iters
cfg.train_dataloader.batch_size = Param2Tune([4, 8])
cfg.train_cfg.max_iters = Param2Tune([20_000, 40_000])
# ... 随后编写一个脚本,指定如何运行单个配置并读取其实验结果:
# -- tools/tune_dist_train.py --
import argparse, subprocess
from alchemy_cat.dl_config import Cfg2TuneRunner, Config
from alchemy_cat.dl_config.examples.read_mmcv_metric import get_metric
parser = argparse.ArgumentParser()
parser.add_argument('--cfg2tune', type=str) # Path to the tunable config
parser.add_argument('--num_gpu', type=int, default=2) # Number of GPUs for each task
args = parser.parse_args()
runner = Cfg2TuneRunner(args.cfg2tune, experiment_root='work_dirs', work_gpu_num=args.num_gpu)
@runner.register_work_fn # Run experiment for each param combination with mmcv official train script
def work(pkl_idx: int, cfg: Config, cfg_pkl: str, cfg_rslt_dir: str, cuda_env: dict[str, str]):
mmcv_cfg = cfg.save_mmcv(cfg_rslt_dir + '/mmcv_config.py')
subprocess.run(f'./tools/dist_train.sh {mmcv_cfg} {args.num_gpu}', env=cuda_env, shell=True)
@runner.register_gather_metric_fn # Optional, gather metric of each config
def gather_metric(cfg: Config, cfg_rslt_dir: str, run_rslt, param_comb) -> dict[str, float]:
return get_metric(cfg_rslt_dir) # {'aAcc': xxx, 'mIoU': xxx, 'mAcc': xxx}
runner.tuning()运行CUDA_VISIBLE_DEVICES=0,1,2,3 python tools/tune_dist_train.py --cfg2tune configs/deeplabv3plus/tune_bs,iter/cfg.py,将自动并行搜索参数空间,汇总得到如下实验结果:
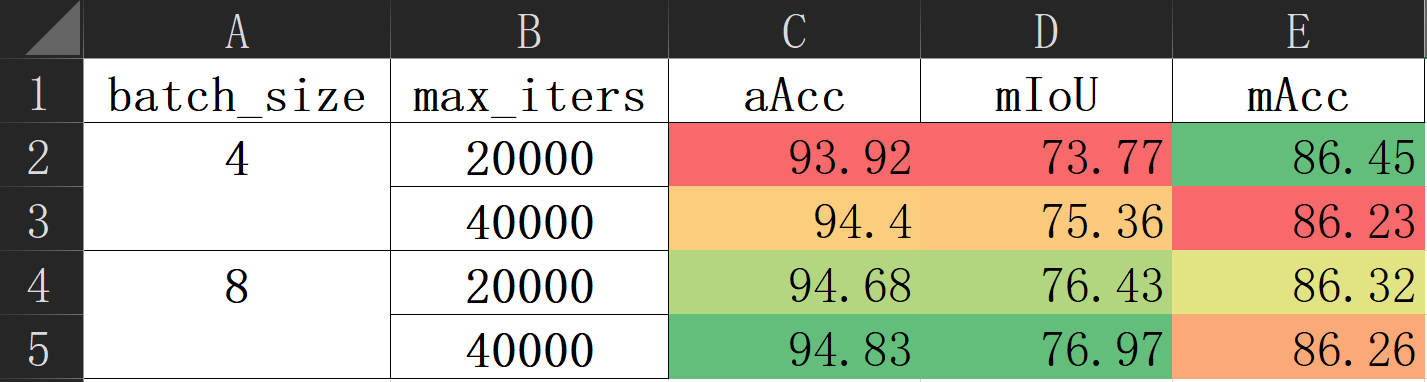
不过,上述配置尚不完整,因为某些超参数之间互相依赖,需要同步调整。例如,学习率应当正比于批次大小。AlchemyCat 利用依赖项来描述这种关系,依赖源一旦修改,相关的依赖项将自动更新以保持一致。包含依赖项的完整配置如下:
# -- configs/deeplabv3plus/tune_bs,iter/cfg.py --
from alchemy_cat import Cfg2Tune, Param2Tune, P_DEP
# Inherit from standard mmcv config.
cfg = Cfg2Tune(caps='configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb4-40k_voc12aug-512x512.py')
# Inherit and override
cfg.model.auxiliary_head.loss_decode.loss_weight = 0.2
# Tuning parameters: grid search batch_size and max_iters
cfg.train_dataloader.batch_size = Param2Tune([4, 8])
cfg.train_cfg.max_iters = Param2Tune([20_000, 40_000])
# Dependencies:
# 1) learning rate increase with batch_size
cfg.optim_wrapper.optimizer.lr = P_DEP(lambda c: (c.train_dataloader.batch_size / 8) * 0.01)
# 2) end of param_scheduler increase with max_iters
@cfg.set_DEP()
def param_scheduler(c):
return dict(
type='PolyLR',
eta_min=1e-4,
power=0.9,
begin=0,
end=c.train_cfg.max_iters,
by_epoch=False)Note
上面例子中,定义依赖项看似画蛇添足——它们其实可以被直接算出。但是,当结合继承功能时,将依赖项定义在基配置中可以带来极大便利:这样,可调配置就可以专注于搜索关键超参数,而无需处理那些繁琐的依赖细节。更贴切的例子参见文档。
pip install alchemy-cat如何从 YAML / YACS / MMCV 迁移
σ`∀´)σ 开玩笑的啦!不需要迁移。AlchemyCat 支持直接读写 YAML、YACS、MMCV 配置文件:
from alchemy_cat.dl_config import load_config, Config
# READ YAML / YACS / MMCV config to alchemy_cat.Config
cfg = load_config('path/to/yaml_config.yaml or yacs_config.py or mmcv_config.py')
# Init alchemy_cat.Config with YAML / YACS / MMCV config
cfg = Config('path/to/yaml_config.yaml or yacs_config.py or mmcv_config.py')
# alchemy_cat.Config inherits from YAML / YACS / MMCV config
cfg = Config(caps='path/to/yaml_config.yaml or yacs_config.py or mmcv_config.py')
print(cfg.model.backbone) # Access config item
cfg.save_yaml('path/to/save.yaml') # Save to YAML config
cfg.save_mmcv('path/to/save.py') # Save to MMCV config
cfg.save_py('path/to/save.py') # Save to AlchemyCat config我们还提供了一个脚本,用于转换不同配置格式:
python -m alchemy_cat.dl_config.from_x_to_y --x X --y Y --y_type=yaml/mmcv/alchemy-cat其中:
--x:源配置文件路径,可以是 YAML / YACS / MMCV / AlchemyCat 配置文件。--y:目标配置文件路径。--y_type:目标配置的格式,可以是yaml、mmcv或alchemy-cat。
AlchemyCat 确保配置与实验一一对应,呈双射关系:
config C + algorithm code A ——> reproducible experiment E(C, A)
实验目录是自动创建的,且与配置文件有相同的相对路径。路径可以是多级目录,路径中可以有空格、逗号、等号等。这便于分门别类地管理实验。譬如:
.
├── configs
│ ├── MNIST
│ │ ├── resnet18,wd=1e-5@run2
│ │ │ └── cfg.py
│ │ └── vgg,lr=1e-2
│ │ └── cfg.py
│ └── VOC2012
│ └── swin-T,γ=10
│ └── 10 epoch
│ └── cfg.py
└── experiment
├── MNIST
│ ├── resnet18,wd=1e-5@run2
│ │ └── xxx.log
│ └── vgg,lr=1e-2
│ └── xxx.log
└── VOC2012
└── swin-T,γ=10
└── 10 epoch
└── xxx.log
Tip
最佳实践:避免路径中含有'.'。遵守该最佳实践,cfg.py中能够使用相对导入,其中定义的函数、类能够被pickle。
让我们从一个不完整的例子开始,了解如何书写和加载配置。我们首先创建配置文件:
# -- [INCOMPLETE] configs/mnist/plain_usage/cfg.py --
from torchvision.datasets import MNIST
from alchemy_cat.dl_config import Config
cfg = Config()
cfg.rand_seed = 0
cfg.dt.cls = MNIST
cfg.dt.ini.root = '/tmp/data'
cfg.dt.ini.train = True
# ... Code Omitted.这里我们首先实例化一个Config类别对象cfg,随后通过属性操作.来添加配置项。配置项可以是任意 python 对象,包括函数、方法、类。
Tip
最佳实践:我们推荐直接在配置项中指定函数或类,而不是通过字符串/信号量来控制程序行为。前者支持 IDE 跳转,便于阅读和调试。
Config是python dict的子类,上面代码定义了一个树结构的嵌套字典:
>>> print(cfg.to_dict())
{'rand_seed': 0,
'dt': {'cls': <class 'torchvision.datasets.mnist.MNIST'>,
'ini': {'root': '/tmp/data', 'train': True}}}
Config 实现了 Python dict的所有API:
>>> cfg.keys()
dict_keys(['rand_seed', 'dt'])
>>> cfg['dt']['ini']['root']
'/tmp/data'
>>> {**cfg['dt']['ini'], 'download': True}
{'root': '/tmp/data', 'train': True, 'download': True}
可以用dict(yaml、json)或dict的子类(YACS、mmcv.Config)来初始化Config对象:
>>> Config({'rand_seed': 0, 'dt': {'cls': MNIST, 'ini': {'root': '/tmp/data', 'train': True}}})
{'rand_seed': 0, 'dt': {'cls': <class 'torchvision.datasets.mnist.MNIST'>, 'ini': {'root': '/tmp/data', 'train': True}}}
用.操作读写cfg更加清晰。例如,下面的代码根据配置,创建并初始化MNIST数据集:
>>> dataset = cfg.dt.cls(**cfg.dt.ini)
>>> dataset
Dataset MNIST
Number of datapoints: 60000
Root location: /tmp/data
Split: Train
若访问不存在的键,会返回一个一次性空字典,应当将其视作False:
>>> cfg.not_exit
{}
在主代码中,使用下面代码加载配置:
# # [INCOMPLETE] -- train.py --
from alchemy_cat.dl_config import load_config
cfg = load_config('configs/mnist/base/cfg.py', experiments_root='/tmp/experiment', config_root='configs')
# ... Code Omitted.
torch.save(model.state_dict(), f"{cfg.rslt_dir}/model_{epoch}.pth") # Save all experiment results to cfg.rslt_dir.load_config从configs/mnist/base/cfg.py中导入cfg,并处理继承、依赖。给定实验根目录experiments_root和配置根目录和config_root,load_config会自动创建实验目录experiment/mnist/base并赋值给cfg.rslt_dir,一切实验结果都应当保存到cfg.rslt_dir中。
加载出的cfg默认是只读的(cfg.is_frozen == True)。若要修改,用cfg.unfreeze()解冻cfg。
- 配置文件提供一个
Config对象cfg,其本质是一个树结构的嵌套字典,支持.操作读写。 cfg访问不存在的键时,返回一个一次性空字典,可将其视作False。- 使用
load_config函数加载配置文件,实验目录会自动创建,其路径会赋值给cfg.rslt_dir。
新配置可以继承已有的基配置,写作cfg = Config(caps='base_cfg.py')。新配置只需覆写或新增项目,其余项目将复用基配置。如对基配置:
# -- [INCOMPLETE] configs/mnist/plain_usage/cfg.py --
# ... Code Omitted.
cfg.loader.ini.batch_size = 128
cfg.loader.ini.num_workers = 2
cfg.opt.cls = optim.AdamW
cfg.opt.ini.lr = 0.01
# ... Code Omitted.若要翻倍batch_size,新配置可写作:
# -- configs/mnist/plain_usage,2xbs/cfg.py --
from alchemy_cat.dl_config import Config
cfg = Config(caps='configs/mnist/plain_usage/cfg.py') # Inherit from base config.
cfg.loader.ini.batch_size = 128 * 2 # Double batch size.
cfg.opt.ini.lr = 0.01 * 2 # Linear scaling rule, see https://arxiv.org/abs/1706.02677继承行为类似于dict.update。核心区别在于,若新配置和基配置有同名键,且值都是Config实例(称作“子配置树”),我们递归地在子树间做update。因此,新配置能够在继承cfg.loader.ini.num_workers的同时,修改cfg.loader.ini.batch_size。
>>> base_cfg = load_config('configs/mnist/plain_usage/cfg.py', create_rslt_dir=False)
>>> new_cfg = load_config('configs/mnist/plain_usage,2xbs/cfg.py', create_rslt_dir=False)
>>> base_cfg.loader.ini
{'batch_size': 128, 'num_workers': 2}
>>> new_cfg.loader.ini
{'batch_size': 256, 'num_workers': 2}
若想在新配置中重写整棵子配置树,可将该子树置为 "override",例如:
# -- configs/mnist/plain_usage,override_loader/cfg.py --
from alchemy_cat.dl_config import Config
cfg = Config(caps='configs/mnist/plain_usage/cfg.py') # Inherit from base config.
cfg.loader.ini.override() # Set subtree as whole.
cfg.loader.ini.shuffle = False
cfg.loader.ini.drop_last = False此时,cfg.loader.ini完全由新配置定义:
>>> base_cfg = load_config('configs/mnist/plain_usage/cfg.py', create_rslt_dir=False)
>>> new_cfg = load_config('configs/mnist/plain_usage,2xbs/cfg.py', create_rslt_dir=False)
>>> base_cfg.loader.ini
{'batch_size': 128, 'num_workers': 2}
>>> new_cfg.loader.ini
{'shuffle': False, 'drop_last': False}
自然而然地,基配置可以继承自另一个基配置,即链式继承。
多继承也是支持的,写作cfg = Config(caps=('base.py', 'patch1.py', 'patch2.py', ...)),其建立一条base -> patch1 -> patch2 -> current cfg的继承链。靠右的基配置常作为补丁项,批量添加一组配置。例如下面的patch包括了 CIFAR10 数据集有关配置:
# -- configs/patches/cifar10.py --
import torchvision.transforms as T
from torchvision.datasets import CIFAR10
from alchemy_cat.dl_config import Config
cfg = Config()
cfg.dt.override()
cfg.dt.cls = CIFAR10
cfg.dt.ini.root = '/tmp/data'
cfg.dt.ini.transform = T.Compose([T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])要改用 CIFAR10,新配置只需要继承该补丁即可:
# -- configs/mnist/plain_usage,cifar10/cfg.py --
from alchemy_cat.dl_config import Config
cfg = Config(caps=('configs/mnist/plain_usage/cfg.py', 'alchemy_cat/dl_config/examples/configs/patches/cifar10.py'))>>> cfg = load_config('configs/mnist/plain_usage,cifar10/cfg.py', create_rslt_dir=False)
>>> cfg.dt
{'cls': torchvision.datasets.cifar.CIFAR10,
'ini': {'root': '/tmp/data',
'transform': Compose(
ToTensor()
Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
)}}
继承的实现细节
继承时,我们先拷贝整棵基配置树,再以新配置更新之,确保新配置和基配置的树结构相互隔离——即增、删、改新配置不会影响基配置。因此,更复杂继承关系,如菱形继承也是支持的,只是不太可读,不建议使用。
注意,叶结点的值被引用传递,原地修改将影响整条继承链。
- 新配置借助继承来复用基配置,并覆写、新增一些配置项。
- 新配置递归地更新基配置,使用
Config.override可以退回到dict.update的更新方式。 Config支持链式继承和多继承,可实现更加细粒度的复用。
上一节的例子中,修改新配置的批次大小时,学习率也随之改变。这种一个配置项随着另一个配置项变化的情况,称作『依赖』。
修改某个配置项后,忘记修改它的依赖项,是非常常见的 bug。好在 AlchemyCat 可以定义依赖项,修改依赖的源头,所有依赖项将自动更新。例如:
# -- [INCOMPLETE] configs/mnist/base/cfg.py --
from alchemy_cat.dl_config import Config, DEP
# ... Code Omitted.
cfg.loader.ini.batch_size = 128
# ... Code Omitted.
cfg.opt.ini.lr = DEP(lambda c: c.loader.ini.batch_size // 128 * 0.01) # Linear scaling rule.
# ... Code Omitted.学习率cfg.opt.ini.lr作为依赖项DEP,借助批次大小cfg.loader.ini.batch_size算出。DEP接受一个函数,函数的实参为cfg,并返回依赖项的值。
在新配置中,我们只需修改批次大小,学习率会自动更新:
# -- configs/mnist/base,2xbs/cfg.py --
from alchemy_cat.dl_config import Config
cfg = Config(caps='configs/mnist/base/cfg.py')
cfg.loader.ini.batch_size = 128 * 2 # Double batch size, learning rate will be doubled automatically.>>> cfg = load_config('configs/mnist/base,2xbs/cfg.py', create_rslt_dir=False)
>>> cfg.loader.ini.batch_size
256
>>> cfg.opt.ini.lr
0.02
以下是一个更复杂的例子:
# -- configs/mnist/base/cfg.py --
# ... Code Omitted.
cfg.sched.epochs = 30
@cfg.sched.set_DEP(name='warm_epochs', priority=0) # kwarg `name` is not necessary
def warm_epochs(c: Config) -> int: # warm_epochs = 10% of total epochs
return round(0.1 * c.sched.epochs)
cfg.sched.warm.cls = sched.LinearLR
cfg.sched.warm.ini.total_iters = DEP(lambda c: c.sched.warm_epochs, priority=1)
cfg.sched.warm.ini.start_factor = 1e-5
cfg.sched.warm.ini.end_factor = 1.
cfg.sched.main.cls = sched.CosineAnnealingLR
cfg.sched.main.ini.T_max = DEP(lambda c: c.sched.epochs - c.sched.warm.ini.total_iters,
priority=2) # main_epochs = total_epochs - warm_epochs
# ... Code Omitted.>>> print(cfg.sched.to_txt(prefix='cfg.sched.')) # A pretty print of the config tree.
cfg.sched = Config()
# ------- ↓ LEAVES ↓ ------- #
cfg.sched.epochs = 30
cfg.sched.warm_epochs = 3
cfg.sched.warm.cls = <class 'torch.optim.lr_scheduler.LinearLR'>
cfg.sched.warm.ini.total_iters = 3
cfg.sched.warm.ini.start_factor = 1e-05
cfg.sched.warm.ini.end_factor = 1.0
cfg.sched.main.cls = <class 'torch.optim.lr_scheduler.CosineAnnealingLR'>
cfg.sched.main.ini.T_max = 27
代码中,总训练轮次cfg.sched.epochs是依赖源头,预热轮次 cfg.sched.warm_epochs是总训练轮次的 10%,主轮次cfg.sched.main.ini.T_max是总训练轮次减去预热轮次。修改总训练轮次,预热轮次和主轮次会自动更新。
依赖项cfg.sched.warm_epochs使用Config.set_DEP装饰器来定义。被装饰的函数即DEP的首个参数,用于计算依赖项。依赖项的键名由关键字参数name指定,若缺省,则为被饰函数之名。当依赖项的计算较为复杂时,推荐使用装饰器来定义。
当依赖项依赖另一个依赖项时,必须按正确顺序计算它们。默认的计算顺序是定义顺序。priority参数可以人工指定计算顺序:priority越小,计算越早。譬如上面cfg.sched.warm_epochs被cfg.sched.warm.ini.total_iters依赖,后者又被cfg.sched.main.ini.T_max依赖,故他们的priority依次增加。
- 当一个配置项依赖于另一项时,应定义其为依赖项。改变依赖源头,依赖项会根据计算函数自动计算。
- 依赖项可以通过
DEP(...)或Config.set_DEP装饰器定义。 - 依赖项间相互依赖时,可通过
priority参数指定解算顺序,否则按照定义顺序解算。
组合是另一种复用配置的方式。预定义好的子配置树,可以像积木一样,组合出完整的配置。譬如,下面的子配置树定义了一套学习率策略:
# -- configs/addons/linear_warm_cos_sched.py --
import torch.optim.lr_scheduler as sched
from alchemy_cat.dl_config import Config, DEP
cfg = Config()
cfg.epochs = 30
@cfg.set_DEP(priority=0) # warm_epochs = 10% of total epochs
def warm_epochs(c: Config) -> int:
return round(0.1 * c.epochs)
cfg.warm.cls = sched.LinearLR
cfg.warm.ini.total_iters = DEP(lambda c: c.warm_epochs, priority=1)
cfg.warm.ini.start_factor = 1e-5
cfg.warm.ini.end_factor = 1.
cfg.main.cls = sched.CosineAnnealingLR
cfg.main.ini.T_max = DEP(lambda c: c.epochs - c.warm.ini.total_iters,
priority=2) # main_epochs = total_epochs - warm_epochs在最终配置中,我们直接组合这套学习率策略:
# -- configs/mnist/base,sched_from_addon/cfg.py --
# ... Code Omitted.
cfg.sched = Config('configs/addons/linear_warm_cos_sched.py')
# ... Code Omitted.>>> print(cfg.sched.to_txt(prefix='cfg.sched.')) # A pretty print of the config tree.
cfg.sched = Config()
# ------- ↓ LEAVES ↓ ------- #
cfg.sched.epochs = 30
cfg.sched.warm_epochs = 3
cfg.sched.warm.cls = <class 'torch.optim.lr_scheduler.LinearLR'>
cfg.sched.warm.ini.total_iters = 3
cfg.sched.warm.ini.start_factor = 1e-05
cfg.sched.warm.ini.end_factor = 1.0
cfg.sched.main.cls = <class 'torch.optim.lr_scheduler.CosineAnnealingLR'>
cfg.sched.main.ini.T_max = 27
看起来非常简单!就是将预定义的子配置树,赋值/挂载到最终配置。Config('path/to/cfg.py')返回配置文件中,cfg对象的拷贝(与继承中一样,拷贝树结构以保证对配置的修改相互隔离)。
组合和依赖的实现细节
细心的读者可能会疑惑,
DEP如何决定依赖项计算函数的参数c,具体传入哪个Config对象?在本章的例子中,c的实参是学习率子配置,因此cfg.warm.ini.total_iters的计算函数为lambda c: c.warm_epochs。然而,在上一章的例子中,c是完整配置,cfg.sched.warm.ini.total_iters的计算函数为lambda c: c.sched.warm_epochs。其实,
c的实参是配置树的根节点,在该树上,DEP第一次被挂载。Config在是一棵双向树,DEP第一次被挂载时,会上溯到根节点,记录DEP到根的相对距离。计算时,上溯相同距离,找到对应的配置树,并传入计算函数。要阻止该默认行为,设置
DEP(lambda c: ..., rel=False),此时c的实参总是为完整配置。
最佳实践:组合和继承,其目的都是复用配置。组合更加灵活、低耦合,应当优先使用组合,尽量减少继承层次。
- 可以用预定义的子配置,组合出最终配置。
展开完整样例
学习率相关的子配置树:
# -- configs/addons/linear_warm_cos_sched.py --
import torch.optim.lr_scheduler as sched
from alchemy_cat.dl_config import Config, DEP
cfg = Config()
cfg.epochs = 30
@cfg.set_DEP(priority=0) # warm_epochs = 10% of total epochs
def warm_epochs(c: Config) -> int:
return round(0.1 * c.epochs)
cfg.warm.cls = sched.LinearLR
cfg.warm.ini.total_iters = DEP(lambda c: c.warm_epochs, priority=1)
cfg.warm.ini.start_factor = 1e-5
cfg.warm.ini.end_factor = 1.
cfg.main.cls = sched.CosineAnnealingLR
cfg.main.ini.T_max = DEP(lambda c: c.epochs - c.warm.ini.total_iters,
priority=2) # main_epochs = total_epochs - warm_epochs组合得到的基配置:
# -- configs/mnist/base/cfg.py --
import torchvision.models as model
import torchvision.transforms as T
from torch import optim
from torchvision.datasets import MNIST
from alchemy_cat.dl_config import Config, DEP
cfg = Config()
cfg.rand_seed = 0
# -* Set datasets.
cfg.dt.cls = MNIST
cfg.dt.ini.root = '/tmp/data'
cfg.dt.ini.transform = T.Compose([T.Grayscale(3), T.ToTensor(), T.Normalize((0.1307,), (0.3081,)),])
# -* Set data loader.
cfg.loader.ini.batch_size = 128
cfg.loader.ini.num_workers = 2
# -* Set model.
cfg.model.cls = model.resnet18
cfg.model.ini.num_classes = DEP(lambda c: len(c.dt.cls.classes))
# -* Set optimizer.
cfg.opt.cls = optim.AdamW
cfg.opt.ini.lr = DEP(lambda c: c.loader.ini.batch_size // 128 * 0.01) # Linear scaling rule.
# -* Set scheduler.
cfg.sched = Config('configs/addons/linear_warm_cos_sched.py')
# -* Set logger.
cfg.log.save_interval = DEP(lambda c: c.sched.epochs // 5, priority=1) # Save model at every 20% of total epochs.继承自基配置,批次大小翻倍,轮次数目减半的新配置:
# -- configs/mnist/base,sched_from_addon,2xbs,2÷epo/cfg.py --
from alchemy_cat.dl_config import Config
cfg = Config(caps='configs/mnist/base,sched_from_addon/cfg.py')
cfg.loader.ini.batch_size = 256
cfg.sched.epochs = 15注意,依赖项如学习率、预热轮次、主轮次都会自动更新:
>>> cfg = load_config('configs/mnist/base,sched_from_addon,2xbs,2÷epo/cfg.py', create_rslt_dir=False)
>>> print(cfg)
cfg = Config()
cfg.override(False).set_attribute('_cfgs_update_at_parser', ('configs/mnist/base,sched_from_addon/cfg.py',))
# ------- ↓ LEAVES ↓ ------- #
cfg.rand_seed = 0
cfg.dt.cls = <class 'torchvision.datasets.mnist.MNIST'>
cfg.dt.ini.root = '/tmp/data'
cfg.dt.ini.transform = Compose(
Grayscale(num_output_channels=3)
ToTensor()
Normalize(mean=(0.1307,), std=(0.3081,))
)
cfg.loader.ini.batch_size = 256
cfg.loader.ini.num_workers = 2
cfg.model.cls = <function resnet18 at 0x7f5bcda68a40>
cfg.model.ini.num_classes = 10
cfg.opt.cls = <class 'torch.optim.adamw.AdamW'>
cfg.opt.ini.lr = 0.02
cfg.sched.epochs = 15
cfg.sched.warm_epochs = 2
cfg.sched.warm.cls = <class 'torch.optim.lr_scheduler.LinearLR'>
cfg.sched.warm.ini.total_iters = 2
cfg.sched.warm.ini.start_factor = 1e-05
cfg.sched.warm.ini.end_factor = 1.0
cfg.sched.main.cls = <class 'torch.optim.lr_scheduler.CosineAnnealingLR'>
cfg.sched.main.ini.T_max = 13
cfg.log.save_interval = 3
cfg.rslt_dir = 'mnist/base,sched_from_addon,2xbs,2÷epo'
训练代码:
# -- train.py --
import argparse
import json
import torch
import torch.nn.functional as F
from rich.progress import track
from torch.optim.lr_scheduler import SequentialLR
from alchemy_cat.dl_config import load_config
from utils import eval_model
parser = argparse.ArgumentParser(description='AlchemyCat MNIST Example')
parser.add_argument('-c', '--config', type=str, default='configs/mnist/base,sched_from_addon,2xbs,2÷epo/cfg.py')
args = parser.parse_args()
# Folder 'experiment/mnist/base' will be auto created by `load` and assigned to `cfg.rslt_dir`
cfg = load_config(args.config, experiments_root='/tmp/experiment', config_root='configs')
print(cfg)
torch.manual_seed(cfg.rand_seed) # Use `cfg` to set random seed
dataset = cfg.dt.cls(**cfg.dt.ini) # Use `cfg` to set dataset type and its initial parameters
# Use `cfg` to set changeable parameters of loader,
# other fixed parameter like `shuffle` is set in main code
loader = torch.utils.data.DataLoader(dataset, shuffle=True, **cfg.loader.ini)
model = cfg.model.cls(**cfg.model.ini).train().to('cuda') # Use `cfg` to set model
# Use `cfg` to set optimizer, and get `model.parameters()` in run time
opt = cfg.opt.cls(model.parameters(), **cfg.opt.ini, weight_decay=0.)
# Use `cfg` to set warm and main scheduler, and `SequentialLR` to combine them
warm_sched = cfg.sched.warm.cls(opt, **cfg.sched.warm.ini)
main_sched = cfg.sched.main.cls(opt, **cfg.sched.main.ini)
sched = SequentialLR(opt, [warm_sched, main_sched], [cfg.sched.warm_epochs])
for epoch in range(1, cfg.sched.epochs + 1): # train `cfg.sched.epochs` epochs
for data, target in track(loader, description=f"Epoch {epoch}/{cfg.sched.epochs}"):
F.cross_entropy(model(data.to('cuda')), target.to('cuda')).backward()
opt.step()
opt.zero_grad()
sched.step()
# If cfg.log is defined, save model to `cfg.rslt_dir` at every `cfg.log.save_interval`
if cfg.log and epoch % cfg.log.save_interval == 0:
torch.save(model.state_dict(), f"{cfg.rslt_dir}/model_{epoch}.pth")
eval_model(model)
if cfg.log:
eval_ret = eval_model(model)
with open(f"{cfg.rslt_dir}/eval.json", 'w') as json_f:
json.dump(eval_ret, json_f)运行python train.py --config 'configs/mnist/base,sched_from_addon,2xbs,2÷epo/cfg.py',将会按照配置文件中设置,使用train.py训练,并将结果保存到/tmp/experiment/mnist/base,sched_from_addon,2xbs,2÷epo目录中。
在上面的例子中,每运行一次python train.py --config path/to/cfg.py,就针对一组参数,得到一份对应的实验结果。
然而,很多时候,我们需要网格搜索参数空间,寻找最优的参数组合。若为每一组参数组合都写一个配置,既辛苦也容易出错。那能不能在一个『可调配置』中,定义整个参数空间。随后让程序自动地遍历所有参数组合,对每组参数生成一个配置,运行配置,并汇总所有实验结果以供比较。
自动调参机遍历可调配置的参数组合,生成N个子配置,运行得到N份实验结果,并将所有实验结果总结到 excel 表格中:
config to be tuned T ───> config C1 + algorithm code A ───> reproducible experiment E1(C1, A) ───> summary table S(T,A)
│ │
├──> config C2 + algorithm code A ───> reproducible experiment E1(C2, A) ──│
... ...
使用自动调参机,首先需要写一个可调配置:
# -- configs/tune/tune_bs_epoch/cfg.py --
from alchemy_cat.dl_config import Cfg2Tune, Param2Tune
cfg = Cfg2Tune(caps='configs/mnist/base,sched_from_addon/cfg.py')
cfg.loader.ini.batch_size = Param2Tune([128, 256, 512])
cfg.sched.epochs = Param2Tune([5, 15])其写法与上一章中的普通配置非常类似,同样支持.读写、继承、依赖、组合等特性。区别在于:
- 可调配置的的类型是
Config的子类Cfg2Tune。 - 对需要网格搜索的参数,定义为
Param2Tune([v1, v2, ...]),其中v1, v2, ...是参数的可选值。
上面的可调配置,会搜索一个 3×2=6 大小的参数空间,并生成如下6个子配置:
batch_size epochs child_configs
128 5 configs/tune/tune_bs_epoch/batch_size=128,epochs=5/cfg.pkl
15 configs/tune/tune_bs_epoch/batch_size=128,epochs=15/cfg.pkl
256 5 configs/tune/tune_bs_epoch/batch_size=256,epochs=5/cfg.pkl
15 configs/tune/tune_bs_epoch/batch_size=256,epochs=15/cfg.pkl
512 5 configs/tune/tune_bs_epoch/batch_size=512,epochs=5/cfg.pkl
15 configs/tune/tune_bs_epoch/batch_size=512,epochs=15/cfg.pkl
设置Param2Tune的priority参数,可以指定参数的搜索顺序。默认为定义顺序。设置optional_value_names参数,可以为参数值指定可读的名字。例如:
# -- configs/tune/tune_bs_epoch,pri,name/cfg.py --
from alchemy_cat.dl_config import Cfg2Tune, Param2Tune
cfg = Cfg2Tune(caps='configs/mnist/base,sched_from_addon/cfg.py')
cfg.loader.ini.batch_size = Param2Tune([128, 256, 512], optional_value_names=['1xbs', '2xbs', '4xbs'], priority=1)
cfg.sched.epochs = Param2Tune([5, 15], priority=0)其搜索空间为:
epochs batch_size child_configs
5 1xbs configs/tune/tune_bs_epoch,pri,name/epochs=5,batch_size=1xbs/cfg.pkl
2xbs configs/tune/tune_bs_epoch,pri,name/epochs=5,batch_size=2xbs/cfg.pkl
4xbs configs/tune/tune_bs_epoch,pri,name/epochs=5,batch_size=4xbs/cfg.pkl
15 1xbs configs/tune/tune_bs_epoch,pri,name/epochs=15,batch_size=1xbs/cfg.pkl
2xbs configs/tune/tune_bs_epoch,pri,name/epochs=15,batch_size=2xbs/cfg.pkl
4xbs configs/tune/tune_bs_epoch,pri,name/epochs=15,batch_size=4xbs/cfg.pk
我们还可以在参数间设置约束条件,裁剪掉不需要的参数组合,如下面例子约束总迭代数不超过 15×128:
# -- configs/tune/tune_bs_epoch,subject_to/cfg.py --
from alchemy_cat.dl_config import Cfg2Tune, Param2Tune
cfg = Cfg2Tune(caps='configs/mnist/base,sched_from_addon/cfg.py')
cfg.loader.ini.batch_size = Param2Tune([128, 256, 512])
cfg.sched.epochs = Param2Tune([5, 15],
subject_to=lambda cur_val: cur_val * cfg.loader.ini.batch_size.cur_val <= 15 * 128)其搜索空间为:
batch_size epochs child_configs
128 5 configs/tune/tune_bs_epoch,subject_to/batch_size=128,epochs=5/cfg.pkl
15 configs/tune/tune_bs_epoch,subject_to/batch_size=128,epochs=15/cfg.pkl
256 5 configs/tune/tune_bs_epoch,subject_to/batch_size=256,epochs=5/cfg.pkl
我们还需要写一小段脚本来运行自动调参机:
# -- tune_train.py --
import argparse, json, os, subprocess, sys
from alchemy_cat.dl_config import Config, Cfg2TuneRunner
parser = argparse.ArgumentParser(description='Tuning AlchemyCat MNIST Example')
parser.add_argument('-c', '--cfg2tune', type=str)
args = parser.parse_args()
# Will run `torch.cuda.device_count() // work_gpu_num` of configs in parallel
runner = Cfg2TuneRunner(args.cfg2tune, experiment_root='/tmp/experiment', work_gpu_num=1)
@runner.register_work_fn # How to run config
def work(pkl_idx: int, cfg: Config, cfg_pkl: str, cfg_rslt_dir: str, cuda_env: dict[str, str]) -> ...:
subprocess.run([sys.executable, 'train.py', '-c', cfg_pkl], env=cuda_env)
@runner.register_gather_metric_fn # How to gather metric for summary
def gather_metric(cfg: Config, cfg_rslt_dir: str, run_rslt: ..., param_comb: dict[str, tuple[..., str]]) -> dict[str, ...]:
return json.load(open(os.path.join(cfg_rslt_dir, 'eval.json')))
runner.tuning()上面的脚本执行了如下操作:
-
传入可调配置的路径,实例化调参机
runner = Cfg2TuneRunner(...)。
自动调参机默认逐个运行子配置。设置参数work_gpu_num,可以并行运行len(os.environ['CUDA_VISIBLE_DEVICES']) // work_gpu_num个子配置。 -
注册工作函数,该函数用于运行单个子配置。函数参数为:
pkl_idx:子配置的序号cfg:子配置cfg_pkl:子配置的 pickle 保存路径cfg_rslt_dir:子配置的实验目录。cuda_env:如果设置了work_gpu_num,那么cuda_env会为并行子配置分配不重叠的CUDA_VISIBLE_DEVICES环境变量。
一般而言,我们只需要将
cfg_pkl作为配置文件(load_cfg支持读取 pickle 保存的配置)传入训练脚本即可。对深度学习任务,还需要为每个配置设置不同的CUDA_VISIBLE_DEVICES。 -
注册汇总函数。汇总函数对每个实验结果,返回格式为
{metric_name: metric_value}的字典。调参机会自动遍历所有实验结果,汇总到一个表格中。汇总函数接受如下参数:-
cfg:子配置 -
cfg_rslt_dir:子配置的实验目录 -
run_rslt:工作函数的返回值 -
param_comb:子配置的参数组合。一般我们只需要到
cfg_rslt_dir中读取实验结果并返回即可。
-
-
调用
runner.tuning(),开始自动调参。
调参结束后,将打印调参结果:
Metric Frame:
test_loss acc
batch_size epochs
128 5 1.993285 32.63
15 0.016772 99.48
256 5 1.889874 37.11
15 0.020811 99.49
512 5 1.790593 41.74
15 0.024695 99.33
Saving Metric Frame at /tmp/experiment/tune/tune_bs_epoch/metric_frame.xlsx
正如提示信息所言,调参结果还会被保存到 /tmp/experiment/tune/tune_bs_epoch/metric_frame.xlsx 表格中:

Tip
最佳实践:自动调参机独立于标准工作流。在写配置和代码时,先不要考虑调参。调参时,再写一点点额外的代码,定义参数空间,指定算法的调用和结果的获取方式。调参完毕后,剥离调参机,只发布最优的配置和算法。
- 可以在可调配置
Cfg2Tune中,使用Param2Tune定义参数空间。 - 自动调参机
Cfg2TuneRunner会遍历参数空间,生成子配置,运行子配置,并汇总实验结果。
展开进阶
Config的__str__方法被重载,以.分隔的键名,美观地打印树结构:
>>> cfg = Config()
>>> cfg.foo.bar.a = 1
>>> cfg.bar.foo.b = ['str1', 'str2']
>>> cfg.whole.override()
>>> print(cfg)
cfg = Config()
cfg.whole.override(True)
# ------- ↓ LEAVES ↓ ------- #
cfg.foo.bar.a = 1
cfg.bar.foo.b = ['str1', 'str2']
如果所有叶节点都是内置类型,Config的美观打印输出可直接作为 python 代码执行,并得到相同的配置:
>>> exec(cfg.to_txt(prefix='new_cfg.'), globals(), (l_dict := {}))
>>> l_dict['new_cfg'] == cfg
True
对不合法的属性名,Config会回退到dict的打印格式:
>>> cfg = Config()
>>> cfg['Invalid Attribute Name'].foo = 10
>>> cfg.bar['def'] = {'a': 1, 'b': 2}
>>> print(cfg)
cfg = Config()
# ------- ↓ LEAVES ↓ ------- #
cfg['Invalid Attribute Name'].foo = 10
cfg.bar['def'] = {'a': 1, 'b': 2}
对深度学习任务,我们建议用init_env代替load_config,在加载配置之余,init_env还可以初始化深度学习环境,譬如设置 torch 设备、梯度、随机种子、分布式训练:
from alchemy_cat.torch_tools import init_env
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', type=str)
parser.add_argument('--local_rank', type=int, default=-1)
args = parser.parse_args()
device, cfg = init_env(config_path=args.config, # config file path,read to `cfg`
is_cuda=True, # if True,`device` is cuda,else cpu
is_benchmark=bool(args.benchmark), # torch.backends.cudnn.benchmark = is_benchmark
is_train=True, # torch.set_grad_enabled(is_train)
experiments_root="experiment", # root of experiment dir
rand_seed=True, # set python, numpy, torch rand seed. If True, read cfg.rand_seed as seed, else use actual parameter as rand seed.
cv2_num_threads=0, # set cv2 num threads
verbosity=True, # print more env init info
log_stdout=True, # where fork stdout to log file
loguru_ini=True, # config a pretty loguru format
reproducibility=False, # set pytorch to reproducible mode
local_rank=..., # dist.init_process_group(..., local_rank=local_rank)
silence_non_master_rank=True, # if True, non-master rank will not print to stdout, but only log to file
is_debug=bool(args.is_debug)) # is debug mode如果log_stdout=True,init_env还会将sys.stdout、sys.stderr fork 一份到日志文件cfg.rslt_dir/{local-time}.log中。这不会干扰正常的print,但所有屏幕输出都会同时被记录到日志。因此,不再需要手动写入日志,屏幕所见即日志所得。
更详细用法可参见init_env的 docstring。
如果您是 addict 的用户,我们的ADict可以作为addict.Dict的 drop-in replacement:from alchemy_cat.dl_config import ADict as Dict。
ADict 具备 addict.Dict 的所有接口,但重新实现了所有方法,优化了执行效率,覆盖了更多 corner case(如循环引用)。Config其实就是ADict的子类。
如果您没有使用过addict,可以考虑阅读这份文档。研究型代码常常会传递复杂的字典结构,addict.Dict或ADict支持属性读写字典,非常适合处理嵌套字典。
ADict和Config的初始化、继承、组合需要用到一种名为branch_copy的操作,其介于浅拷贝和深拷贝之间,即拷贝树结构,但不拷贝叶节点。ADict.copy,Config.copy,copy.copy(cfg)均会调用branch_copy,而非dict的copy方法。
理论上ADict.branch_copy能够处理循环引用情况,譬如:
>>> dic = {'num': 0,
'lst': [1, 'str'],
'sub_dic': {'sub_num': 3}}
>>> dic['lst'].append(dic['sub_dic'])
>>> dic['sub_dic']['parent'] = dic
>>> dic
{'num': 0,
'lst': [1, 'str', {'sub_num': 3, 'parent': {...}}],
'sub_dic': {'sub_num': 3, 'parent': {...}}}
>>> adic = ADict(dic)
>>> adic.sub_dic.parent is adic is not dic
True
>>> adic.lst[-1] is adic.sub_dic is not dic['sub_dic']
True
对ADict不同,Config的数据结构是双向树,而循环引用将成环。为避免成环,若子配置树被多次挂载到不同父配置,子配置树会先拷贝得到一棵独立的配置树,再进行挂载。正常使用下,配置树中不会出现循环引用。
总而言之,尽管循环引用是被支持的,不过即没有必要,也不推荐使用。
Config.named_branches和Config.named_ckl分别遍历配置树的所有分支和叶节点(所在的分支、键名和值):
>>> list(cfg.named_branches)
[('', {'foo': {'bar': {'a': 1}},
'bar': {'foo': {'b': ['str1', 'str2']}},
'whole': {}}),
('foo', {'bar': {'a': 1}}),
('foo.bar', {'a': 1}),
('bar', {'foo': {'b': ['str1', 'str2']}}),
('bar.foo', {'b': ['str1', 'str2']}),
('whole', {})]
>>> list(cfg.ckl)
[({'a': 1}, 'a', 1), ({'b': ['str1', 'str2']}, 'b', ['str1', 'str2'])]
>>> from alchemy_cat.dl_config import Config
>>> cfg = Config(caps='configs/mnist/base,sched_from_addon/cfg.py')
>>> cfg.loader.ini.batch_size = 256
>>> cfg.sched.epochs = 15
>>> print(cfg)
cfg = Config()
cfg.override(False).set_attribute('_cfgs_update_at_parser', ('configs/mnist/base,sched_from_addon/cfg.py',))
# ------- ↓ LEAVES ↓ ------- #
cfg.loader.ini.batch_size = 256
cfg.sched.epochs = 15
继承时,父配置caps不会被立即更新过来,而是等到load_config时才会被加载。惰性继承使得配置系统可以鸟瞰整条继承链,少数功能有赖于此。
由于config C + algorithm code A ——> reproducible experiment E(C, A),意味着当配置C和算法代码A确定时,总是能复现实验E。因此,建议将配置文件和算法代码一同提交到 Git 仓库中,以便日后复现实验。
我们还提供了一个脚本,运行pyhon -m alchemy_cat.torch_tools.scripts.tag_exps -s commit_ID -a commit_ID,将交互式地列出该 commit 新增的配置,并按照配置路径给 commit 打上标签。这有助于快速回溯历史上某个实验的配置和算法。
work函数通过cuda_env参数,接收Cfg2TuneRunner自动分配的空闲显卡。我们还可以进一步控制『空闲显卡』的定义:
runner = Cfg2TuneRunner(args.cfg2tune, experiment_root='/tmp/experiment', work_gpu_num=1,
block=True, # Try to allocate idle GPU
memory_need=10 * 1024, # Need 10 GB memory
max_process=2) # Max 2 process already ran on each GPU其中:
block: 默认为True。若为False,则总是顺序分配显卡,不考虑空闲与否。memory_need:运行每个子配置需要的显存,单位为 MB。空闲显卡之可用显存必须 ≥memory_need。默认值为-1.,表示需要独占所有显存。max_process:最大已有进程数。空闲显卡已有的进程数必须 ≤max_process。默认值为-1,表示无限制。
Cfg2Tune生成的子配置会被 pickle 保存。然而,若Cfg2Tune定义了形似DEP(lambda c: ...)的依赖项,所存储的匿名函数无法被 pickle。变通方法有:
- 配合装饰器
@Config.set_DEP,将依赖项的计算函数定义为一个全局函数。 - 将依赖项的计算函数定义在一个独立的模块中,然后再传递给
DEP。 - 在父配置
caps中定义依赖项。由于继承的处理是惰性的,Cfg2Tune生成的子配置暂时不包含依赖项。 - 如果依赖源是可调参数,可使用特殊的依赖项
P_DEP,它将于Cfg2Tune生成子配置后、保存为 pickle 前解算。
Config.empty_leaf()结合了Config.clear()和Config.override(),可以得到一棵空且 "override" 的子树。这常用于在继承时表示『删除』语义,即用一个空配置,覆盖掉基配置的某颗子配置树。
cfg是一个Config实例,base_cfg是一个dict实例,cfg.dict_update(base_cfg)、cfg.update(base_cfg)、cfg |= base_cfg的效果与让Config(base_cfg)继承cfg类似。
cfg.dict_update(base_cfg, incremental=True)则确保只做增量式更新——即只会增加cfg中不存在的键,而不会覆盖已有键。