When you're scraping data from the web, proxies play a vital role in ensuring smooth, uninterrupted access. In simple terms, a proxy server acts as a middleman between your scraping tool and the website you're extracting data from. It masks your IP address, making it look like the requests are coming from different locations, which helps you avoid being blocked or throttled by websites.
Choosing the right scraping proxy provider can make a huge difference in how efficiently and effectively you can scrape the data you need. With countless options available, it’s important to know what to look for. In this article, we'll break down what a proxy server is, why it’s a must-have for web scraping, and key factors to consider when selecting the best proxy provider for your scraping needs.
A proxy server acts as a bridge between a user’s device and the internet, forwarding requests to the target server and relaying the server's responses back to the user. This intermediary role not only ensures anonymity but also provides additional layers of functionality essential for tasks like web scraping.
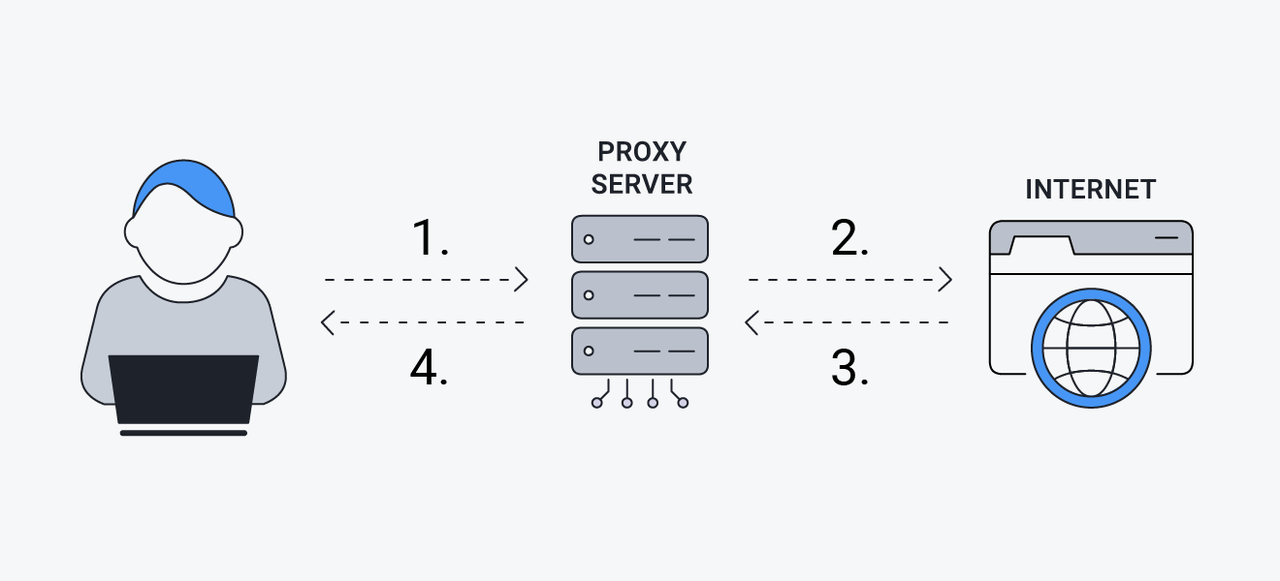
How Does It Work?
- Request Forwarding: When a user sends a request (e.g., to access a website), the proxy server intercepts it and forwards it to the target server.
- Response Relay: The target server processes the request and sends the response back to the proxy, which then relays it to the user.
- IP Masking: The proxy server replaces the user’s IP address with its own, hiding the user’s identity.
- Traffic Filtering: It can filter or modify requests and responses based on predefined rules, such as bypassing geo-restrictions or optimizing bandwidth usage. By acting as an intermediary, proxy servers enable smoother and more secure data scraping while mitigating risks like IP bans or detection by anti-scraping systems.
Web scraping is a powerful tool for gathering valuable data from websites, but it often comes with several challenges. Proxy servers are crucial in overcoming these obstacles, ensuring smooth and efficient scraping.
Common Challenges in Web Scraping:
- IP Blocking: Websites can block IP addresses after multiple requests, making it difficult to continue scraping.
- Anti-Scraping Mechanisms: Advanced detection systems can flag bot-like behavior, preventing further access to the site.
- Geo-Restrictions: Some websites limit access based on geographic location, restricting content for users in certain regions.
How Proxy Servers Help:
- IP Rotation: Proxy servers automatically rotate IP addresses to avoid detection and bypass IP bans. This ensures that scraping activities remain undetected, even with high request volumes.
- Anonymity: By masking the real IP address, proxies help maintain anonymity, preventing websites from tracking or blocking scraping attempts.
- Bypassing Restrictions: Proxy servers can bypass geo-restrictions, allowing users to access region-locked content and scrape data from anywhere.
- Handling CAPTCHAs: Proxies can reduce the likelihood of encountering CAPTCHAs, as rotating IPs can make the scraping process appear more human-like.
When scraping data, choosing the right type of proxy is crucial to improving scraping efficiency and success rate. Different types of proxy servers have their own characteristics and are suitable for different scraping scenarios. There are mainly the following types:
- Residential Proxies
- Datacenter Proxies
- Mobile Proxies
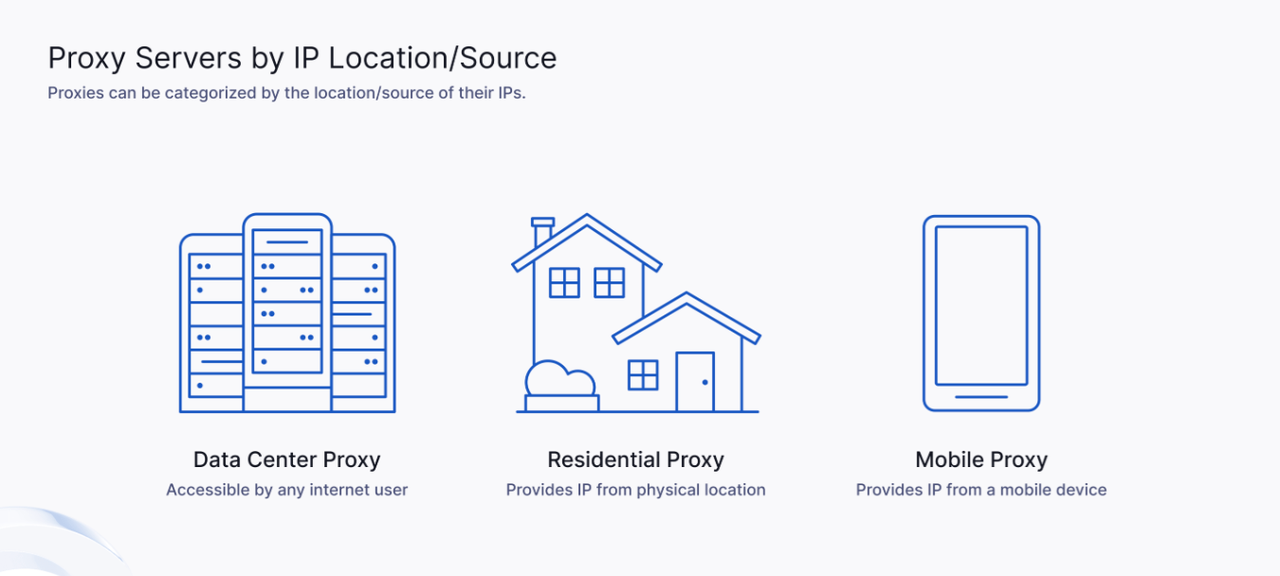
Residential proxies are IP addresses provided through real home network connections. Their biggest advantage is that they look like ordinary user traffic and are therefore not easily detected by anti-crawler mechanisms. They are particularly suitable for scenarios where a large number of requests are required and you do not want to be identified as a crawler by the website.
Datacenter proxies come from data centers and are usually provided by providers through multiple server pools. Compared with residential proxies, the advantage of datacenter proxies is their high speed and low cost, which is very suitable for tasks that require high-frequency scraping. However, since the IP addresses of these proxies do not come from real users, they are easily identified as crawler traffic by websites, especially when a large number of requests come from the same IP, which may trigger a ban.
For users who need to scrape a large amount of data quickly, datacenter proxies are an efficient and cost-effective choice.
Mobile proxies are IP addresses provided by mobile device networks, usually from real mobile phone users. They are very suitable for crawling data related to mobile devices, especially as anti-crawler mechanisms on mobile terminals become stronger. Because they simulate the behavior of real users, mobile proxies can effectively avoid IP blocking and can bypass some anti-crawler mechanisms specifically for data center proxies.
However, mobile proxies are usually more expensive and are suitable for tasks that require high crawling accuracy and success rate.
IPV4 and IPV6 are two different versions of the Internet Protocol, and they also differ in the use of proxies. IPV4 proxy addresses are limited, while IPV6 proxies provide almost unlimited address space. For crawling tasks that require a large number of proxy IPs, IPV6 proxies can provide more options and reduce the risk of IP being blocked.
Related reading: How to Scrape Amazon Search Result Data: Python Guide 2025
When choosing a scraping proxy provider, it is important to consider a few factors to ensure that the choice meets your specific needs and improves the efficiency of your web scraping efforts.
The following are basic criteria to evaluate:
1. Speed and Reliability
Speed is critical for efficient scraping, especially when dealing with large amounts of data or when real-time access is required. A reliable proxy should provide consistent uptime and fast response times to minimize interruptions during scraping tasks.
Reliability ensures that the proxy service is always available without frequent downtime, which could hamper data collection.
2. IP Rotation Capabilities
Effective IP rotation helps avoid detection by changing the IP address used for requests, thereby simulating multiple users. This reduces the likelihood of being blocked or banned from the target website. Look for providers that offer advanced rotation capabilities to more effectively mimic human browsing behavior.
3. Geographic Coverage
The geographic location of the proxy server is critical, especially when you need to access geo-restricted content or want to scrape data from a specific region. Providers with a wide range of IP addresses spread across different locations can help bypass geo-restrictions and improve scraping efficiency.
4. Protocol Compatibility
Make sure the proxy supports the necessary protocols (HTTP, HTTPS, SOCKS) required by your crawler. Some advanced features may also require specific protocol support for optimal performance.
5. Cost Considerations
Evaluate pricing plans based on your budget while considering the long-term value of features, such as fewer blocks and bans, which can save time and resources in the long run. Balance cost against desired features to find the right provider.
Unlock seamless web scraping with Scrapeless Proxy—try it now and experience unparalleled speed, reliability, and efficiency! Click to login in!
Scrapeless is a leading scraping proxy provider. Here are the main reasons why Scrapeless stands out in the market:
1. Extensive proxy network
Scrapeless has a huge proxy pool, including more than 80 million residential IPs, and supports HTTPS & SOCKS5, ensuring comprehensive coverage and high success rate of data extraction
Scrapeless's IPv6 proxy supports multiple protocols, including HTTP, HTTPS, and SOCKS5, making it compatible with a variety of scraping tools and applications. Users can choose the appropriate connection method according to their specific needs.
2. Advanced IP rotation
Scrapeless provides a sophisticated IP rotation function, which changes the IP address after each request, greatly reducing the risk of being detected and blocked by the target website. This feature is essential for maintaining anonymity and ensuring uninterrupted scraping sessions.
3. High uptime and reliability
Scrapeless has an uptime of up to 99.99%, which is essential for businesses that rely on stable data access to run their businesses.
4. Comprehensive API solutions
Scrapeless provides a rich API ecosystem, including dedicated options for different types of data extraction (such as SERP API, Google Trends API, E-commerce Scraping API), which simplifies the scraping process for developers.
5. Ethical data collection practices
Scrapeless always attaches great importance to ethical data collection practices and ensures that its agents are sourced legally. This commitment to ethical standards helps users avoid potential legal issues related to web scraping.
In summary, a proxy server is crucial for effective web scraping, offering anonymity and bypassing restrictions like IP bans. When selecting a proxy provider, consider factors such as speed, stability, and security. While free proxies may seem appealing, they often come with risks like malware and data breaches.
For a reliable and efficient solution, Scrapeless is an excellent choice. With features like automatic IP rotation and built-in anti-scraping tools, it simplifies the scraping process and ensures optimal performance.
Join Scrapeless Discord community today to unlock your free trial of Scrapeless and elevate your web scraping!
1. What is the difference between residential and datacenter proxies?
Residential proxies use IP addresses assigned to real residential devices, making them appear as legitimate users, which helps avoid detection and bans. In contrast, datacenter proxies originate from data centers and cloud servers, offering faster speeds but are more easily identified as non-human traffic, leading to a higher risk of being blocked by websites.
2. Can I use free proxies for web scraping? What are the risks?
While free proxies may seem attractive because they have no cost, they come with significant risks. Specifically include:
- Malware injection: Hackers may steal your data through free proxies, creating security risks.
- Data Breaches: Free proxies may log sensitive information, leading to the risk of data breaches.
- IP spoofing: Using a free proxy can result in your IP being associated with malicious activity, affecting your credibility.
3. Why is IP rotation important for web scraping?
IP rotation is crucial for web scraping as it helps distribute requests across multiple IP addresses, mimicking natural user behavior. This practice minimizes the risk of detection and blocking by target websites, allowing scrapers to maintain access over extended periods. By frequently changing IPs, scrapers can also bypass restrictions imposed by websites on the number of requests from a single IP address.