纯前后端分离的搜索引擎项目实战
本项目是与2019.12.12初步完成,基于java configuration的ssm后台,纯前后端分离项目,并内嵌tomcat,一键启动。
本项目初衷是针对于小范围社区(企业,学校,院系)提供问题解决方案,不断扩充和更新的解决方案库。
本项目所有后台代码和前端js交互逻辑代码均原创
版本参数:
mysql:8.0.11
spring: 5.0.2.RELEASE
mybatis:3.4.6
servlet:4.0.1
tomcat:8.5.33
为啥本项目取名为搜索引擎呢,在长达一周,超过60个小时的编码过程里,时间主要耗费在搜索这块的业务实现,所以最终把他定为搜索引擎的项目。
搜索这一块我总结了一下两点为重点:
1、在庞大的数据量下,如何把关键词更快更准确的检索出来
2、在检索之前,如何过滤掉无效关键词和定位主次关键词,让搜索结果有效的排序。
ok咱们先聊一聊第一个问题,简而言之,就是搜索的效率和精准度。
其实在做项目之前,我有考虑到用es(ElasticSearch)做引擎搜索,不过,我想要去更深一步的发掘mysql的潜力,说白了就是提升自己的mysql能力,更大程度上,我是把es看成了一种工具,程序员嘛,有的时候同样业务效果,更喜欢去深究底层的东西。
比较难搞的事情就是在最初课程学习mysql的时候,并没有去深入了解检索效率的问题,以至于数据库的水平就停留在最基础的sql语句水平,所以在项目之初,想不到如何入手这个搜索引擎。
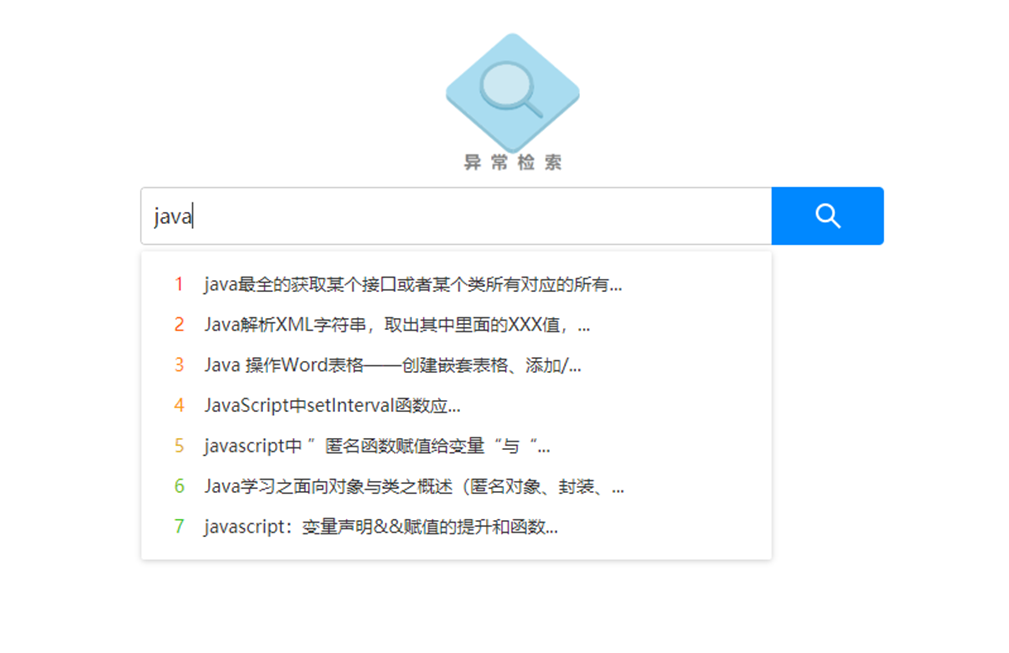
搜索=模糊匹配?
说到搜索引擎,大部分人脑子里都会出现模糊匹配这个词组,所以呢,最初就是用sql语句like去实现最基本的检索需求
select * from tableName where fieldName like '%java%'然而在最初的3w条模拟数据下,我检索一个关键词'java',检索出来的时间居然是45s,并且在查询过程中,磁盘的读取利用率可以在任务管理器看到是100%。
amazing!那这还怎么玩,不考虑查询并发的问题,一个人查询就能把磁盘读取拉满,还有45s的等待时间,如果放网页上,那不直接就请求超时。
那怎么办呢,原因是刚刚的sql语句like 如果是%%双百分号就是前后匹配,走的是全文检索,意思是一条一条的问,不会走咱们的索引,所以即便在标题关键词里面加入索引也不会优化目前的搜索速度,如何改呢,既然他不走索引,咱们要强制让他走索引,在翻阅相关资料后发现后匹配%即'java%'这种形式,是可以走索引的,这样一来虽然减少了匹配的条目,比如,在标题中央出现关键词,他就不会检索出来,但是现在的检索效率在测试后发现,从45s降到了惊人的0.6s!
select * from tableName where fieldName like 'java%'然后在网上传的locate函数即
select * from tableName where locate('keywords',fieldName)其实在很大程度上,和普通的like匹配无差,也不会走索引。
在此基础上,因为模拟数据目前只有3w条,我就暂时没有去优化sql,而是更关心业务部分的东西,然而当最后的测试数据到了100w条的时候(总sql文件4.3G)的时候,全文检索一遍,即便是后置匹配走索引,查询时间居然是120s+!
这可不得了,查阅了各方的文章都没有合适的回答,在最后要交付答卷前的2小时的时候,无聊的我尝试了两个sql语句
select * from tableName limit 0,20;
select id from tableName limit 0,20;
select * from tableName where id = ${id}看似业务效果相同的两个sql语句,甚至第二个感觉还会耗费更多的查询次数,然而实际效果是可能第二个跑完所有的20条数据,第一个连1/10的结果都没跑完,这里肯定有的同学会讲怎么可能,然而在庞大的100w条数据的支撑下,事实就是如此的不敢相信,最后检索的速度由最初的120s,稳定在了0.3s以内,也就是说,我在100w条数据内,不管搜索什么关键词,都能在1s以内把结果呈现给我。当然刚刚的第二条sql语句的第二条需要在后台里面循环去执行,ok,到此,搜索的效率就提升上来了。
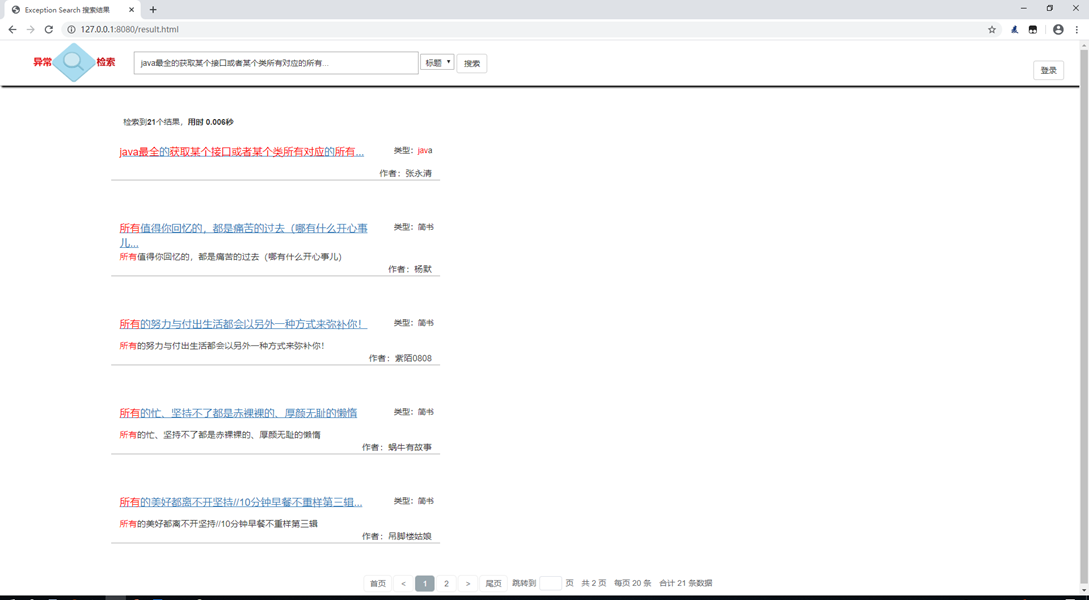
这里的精准度,咱们先从原理上聊一聊,在后台吧数据拿到持久层之后,咱们可以从哪些方面去增加检索的精准度?细心地小伙伴肯定会发现,第一个是检索词的优化,另一个就是检索结果的良好排序,检索词的优化,咱们放到下一节代码层面上讲,这里咱们先把检索结果排序讲一讲。
咱们知道,mysql like语句查询出来的结果,他是乱序的,除非你用order by 等等排序的限定词他会展示一定程度上的有序(发表时间,id顺序,首字母顺序等等),然而关乎查询精准度,咱们根本不回去关心他的id在前在后,发表时间是否是几年前或者今年(不过这个有可能有关结果更新程度),咱们最为关心的是什么?当然是查询出来的结果和关键词是否搭配,和关键词匹配度最高的结果条目。
order by length(fieldName) desc以上就是在查询之后排序出和关键词字段匹配度最高的顺序。
ok,咱们接下来讨论一下第二个问题:
这一部分,就是java代码呈现了
说难也不难,每一句代码大家都看得懂,我大概解读一下,在前端拿回关键词之前,先用trim把两端的空格去掉(当然纯前后端分离我想的是最后在后端接收的时候也吧前后端的空格去掉一下),拿到关键词之后咱们用split 通过正则表达式把空格以及很多个空格和一些高频的介词过滤掉
String[] split = keywords.split("\\s+|、|,|。|;|?|!|,|\\.|;|\\?|!|]|的|得|地|中|内|外");当然我这里肯定还没有把介词写完整,那么现在的数组内部就得到了几个主要的关键词,当然里头还需要把空串给过滤掉
List<String> keywordsList = new ArrayList<>();
for (String s:
split) {
//处理介词空串
if(!"".equals(s)){
keywordsList.add(s);
}
}空串过滤掉之后,就是最终我们要进行检索的关键词组,但是还要考虑如果这个人只输入了介词或者空格,因为咱们是前后端分离,要从接口层面把反馈给写好,所以良好的提示是必不可少的:
//如果只输入了介词直接返回
if(keywordsList.size()==0){
return ResponseModel.failResModel(0,"please input args");
}最后的关键词集合需要把最初的关键词也加入,举个例子spring中的ioc,那么这个中的其实并不是为了隔离每个关键词,我们需要把整个词条也纳入关键词组
keywordsList.add(keywords);这样我们的无效搜索和关键词优化就处理了。
在这两个搜索重点之后呢,另外一个比较重要的就是用户体验。
所谓高亮,就是把搜索出来的词条里面的关键词的部分,给加上红色或者其他颜色,标识目前词条和用户所需关键词的匹配度,例如百度搜索的东西,这样看似很简单的东西,我用了两部分来完成,一部分是后台过滤无效关键词后,给出有效关键词,另一部分是前端把有效关键词拿到,通过遍历迭代把词组内部的关键词定位并染色。
后台过滤无效关键词在上一部分已经给出,这里给出返回给前端的关键词语句:返回的格式是关键词1,关键词2
//其他优先级关键词
for (String s:
keywordsList) {
realKeywords.append(s+",");
}
return ResponseModel.successResModel(1,realKeywords.toString().trim().substring(0,realKeywords.length()-1), resList.toArray());realKeywords这个集合就是有效关键词组
前端高亮算法:
//文字高亮 解决方案2 先把结果内容转小写 去匹配关键字的小写,匹配到了记录index,str.length 在原结果串取出来,再进行replace()
//1、取出关键词的小写
if(e.result != undefined){
//转小写
var lowercaseKeywords = e.desc.toLowerCase().split(",");
for (var i = 0; i < e.result.length; i++) {
//2、取结果串的小写
var lowerResContent = e.result[i].title.toLowerCase();
//3、匹配
//找到后装到index[]
var index=[];
for (var j = 0; j < lowercaseKeywords.length; j++) {
index.push(lowerResContent.indexOf(lowercaseKeywords[j]));
}
// 如果index!=-1 取出原串的值 然后替换 装入需要高亮的原关键词组
var keywordsFromRes = []
for (var j = 0; j < index.length; j++) {
if(index[j] != -1){
//截取的截止部位是拿到的关键词串数组中的串的长度
keywordsFromRes.push(e.result[i].title.substr(index[j],Number(lowercaseKeywords[j].length)));
}
}
//进行替换
var title= e.result[i].title;
var type = e.result[i].type;
var desc = e.result[i].desc;
for (var j = 0; j < keywordsFromRes.length; j++) {
title = title.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
type = type.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
desc = desc.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
}
var author = e.result[i].author;
var views = e.result[i].views;简单讲一下js算法的原理,在后台拿到有效关键词后先把所有的关键词转小写toLowerCase(),因为咱们前面后台的返回结果是把每个有效关键词用逗号隔开,所以我们取得时候,直接就以逗号给分割,分割之后我们就得到了一个一个的全小写关键词,然后我们把搜索结果全转小写,用于匹配小写关键词,然后我们用indexOf把定位关键词的位置,
for (var j = 0; j < lowercaseKeywords.length; j++) {
index.push(lowerResContent.indexOf(lowercaseKeywords[j]));
}定位到之后我们装入一个集合,作为下标集合,我们用于遍历原检索结果。这里需要注意的是,js的substr和java的String类里头的subString是有很大差别的,js的处理是起始地址和截取长度,java的是起始地址和终止地址,小伙伴一定要注意:
var keywordsFromRes = []
for (var j = 0; j < index.length; j++) {
if(index[j] != -1){
//截取的截止部位是拿到的关键词串数组中的串的长度
keywordsFromRes.push(e.result[i].title.substr(index[j],Number(lowercaseKeywords[j].length)));
}
}
//进行替换
var title= e.result[i].title;
var type = e.result[i].type;
var desc = e.result[i].desc;
for (var j = 0; j < keywordsFromRes.length; j++) {
title = title.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
type = type.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
desc = desc.replace(new RegExp(keywordsFromRes[j],'g') ,"<em>"+keywordsFromRes[j]+"</em>");
}最终我们就可以把已经替换好高亮词汇的检索结果呈现到网页上!
本项目启动,使用的是内嵌tomcat的方式,摒弃了传统的外置tomcat,项目启动更快捷,更方便
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-core</artifactId>
<version>8.5.33</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.tomcat.embed/tomcat-embed-jasper -->
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<version>8.5.33</version>
</dependency>
public static void run(){
Tomcat tomcat = new Tomcat();
tomcat.setPort(8080);
// 标识tomcat启动为webapp
tomcat.addWebapp("/","D://test/");
try {
// tomcat启动
tomcat.start();
// tomcat监听用户接入
tomcat.getServer().await();
} catch (LifecycleException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
run();
}mvc和ioc容器配置文件使用的是javaConfiguration的方式配置:
package xyz.zjhwork.springApplicationStarter.mvcConf;
import com.alibaba.fastjson.support.spring.FastJsonHttpMessageConverter;
import org.apache.ibatis.datasource.pooled.PooledDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.mapper.MapperScannerConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.http.MediaType;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import xyz.zjhwork.interceptor.LoginInterceptor;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.List;
import java.util.Properties;
@Configuration
@EnableWebMvc
@ComponentScan("xyz.zjhwork")
public class MvcConf implements WebMvcConfigurer {
@Override
public void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
// 字符转换 包括解决中文乱码
FastJsonHttpMessageConverter fastJsonHttpMessageConverter = new FastJsonHttpMessageConverter();
fastJsonHttpMessageConverter.setSupportedMediaTypes(MediaType.parseMediaTypes("text/html;charset=utf-8"));
converters.add(fastJsonHttpMessageConverter);
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
//拦截器注册
registry.addInterceptor(new LoginInterceptor()).addPathPatterns("/newException").addPathPatterns("/")
.addPathPatterns("/userStatus").addPathPatterns("/userExit").addPathPatterns("/newException").addPathPatterns("/myListException").addPathPatterns("/userInfo")
.addPathPatterns("/isFavByUsernameAndExceptionId").addPathPatterns("/findFavByUsername").addPathPatterns("/deleteFavFromFavByUsernameAndExceptionId").addPathPatterns("/addFavByUsernameAndExceptionId")
.addPathPatterns("/isAproByUsernameAndExceptionId").addPathPatterns("/addAproByUsernameAndExceptionId").addPathPatterns("/insertComment").addPathPatterns("/findHistoryByUsername").addPathPatterns("/userInfoUpdate")
;
}
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/css/**").addResourceLocations("classpath:/static/css/");
registry.addResourceHandler("/js/**").addResourceLocations("classpath:/static/js/");
registry.addResourceHandler("/img/**").addResourceLocations("classpath:/static/img/");
registry.addResourceHandler("/theme/**").addResourceLocations("classpath:/static/theme/");
// 静态资源存放
registry.addResourceHandler("/*.html").addResourceLocations("classpath:/static/");
}
/**
* mybatisConf
*
* @return
*/
@Bean("pooledDataSource")
public DataSource dataSource() {
//加载db.properties 读取数据库基本信息
Properties pop = new Properties();
try {
pop.load(this.getClass().getClassLoader().getResourceAsStream("db.properties"));
} catch (IOException e) {
e.printStackTrace();
}
PooledDataSource dataSource = new PooledDataSource();
try {
dataSource.setDriver(pop.getProperty("jdbc.driver"));
dataSource.setUsername(pop.getProperty("jdbc.username"));
dataSource.setPassword(pop.getProperty("jdbc.password"));
dataSource.setUrl(pop.getProperty("jdbc.url"));
dataSource.setDefaultAutoCommit(true);
dataSource.setPoolMaximumActiveConnections(20);
dataSource.setPoolMaximumIdleConnections(0);
} catch (Exception e) {
e.printStackTrace();
}
return dataSource;
}
@Bean("sqlSessionFactoryBean")
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws IOException {
SqlSessionFactory factory;
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
//加载mapper.xml
ResourcePatternResolver resolver = new ClassPathXmlApplicationContext();
bean.setMapperLocations(resolver.getResources("classpath*:/daoMappers/*.xml"));
try {
factory = bean.getObject();
} catch (Exception e) {
throw new RuntimeException(e);
}
return factory;
}
@Bean("mapperScannerConfigurer")
public MapperScannerConfigurer mapperScannerConfigurer() {
MapperScannerConfigurer mapperScannerConfigurer = new MapperScannerConfigurer();
mapperScannerConfigurer.setBasePackage("xyz.zjhwork.dao");
mapperScannerConfigurer.setSqlSessionFactoryBeanName("sqlSessionFactoryBean");
return mapperScannerConfigurer;
}
}
本文只提供本项目的核心算法和思想,另外本项目还包含了markdown富文本编译器的整合等的,本项目github地址:
https://github.com/zjhChester/ExceptionSearch.git
最后放两张效果图在上面供大家参考,需要帮助或者沟通的同学们联系邮箱zjhChester@gmail.com。